Google has added new models for code completion and more efficient inference to the Gemma family. Terms of use have been made more flexible.
Google announced today that it is expanding its Gemma family of AI models. Gemma was first released in February and includes lightweight models that use the same technology as Google's larger Gemini models. It's Google's foot in the door in the open-source market.
Gemma for code
There are three new versions of CodeGemma, a model that helps programmers write code:
- A pre-trained 7 billion parameter model for completing code and generating new code
- A 7 billion parameter model optimized for chatting about code and following instructions
- A pre-trained 2 billion parameter model for fast code completion on local devices

CodeGemma has been trained on 500 billion tokens of data from web documents, math, and code. It can write correct and meaningful code in Python, JavaScript, Java, and other popular programming languages. Google says CodeGemma is meant to let developers write less repetitive code and focus on harder tasks.
Gemma for more efficient inference
Google also released RecurrentGemma, a separate model that uses recurrent neural networks and local attention to be more memory efficient. It performs similarly to the 2 billion parameter Gemma model, but has some benefits:
- It uses less memory for longer text generation on devices with limited memory, like single GPUs or CPUs.
- It can process text faster by using larger batch sizes and generating more words per second.
- It advances AI research by showing how non-transformer models can still perform well.
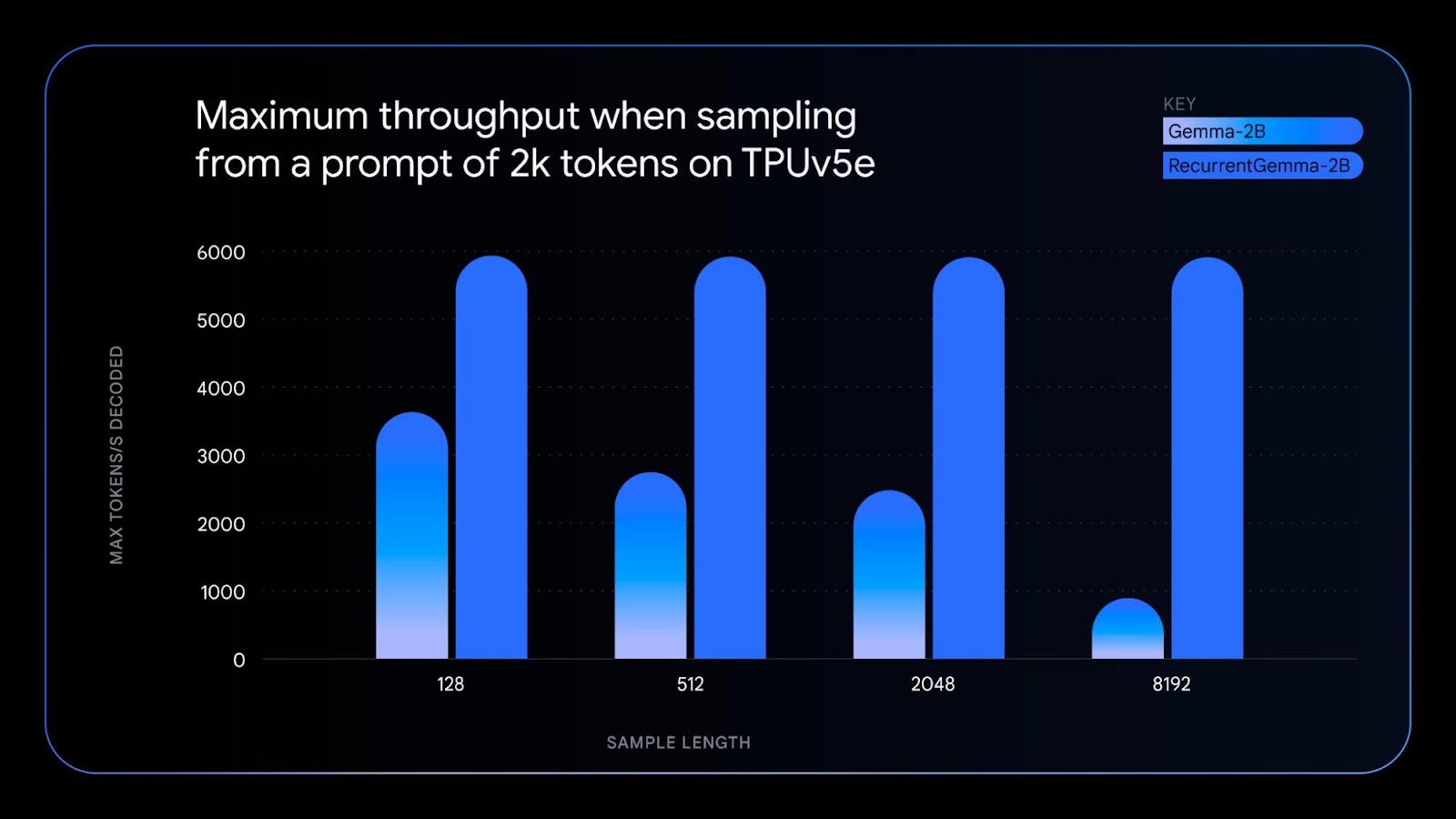
Google also updated the original Gemma models to version 1.1 with performance improvements, bug fixes, and more flexible usage terms.
The new models are now available on Kaggle, Nvidia NIM APIs, Hugging Face and in the Vertex AI Model Garden. They work with tools including JAX, PyTorch, Hugging Face Transformers, Gemma.cpp, Keras, NVIDIA NeMo, TensorRT-LLM, Optimum-NVIDIA, and MediaPipe.


