Google's AVIS tries to answer questions about images where the information is not readily available, such as the date an airline was founded or the year a car was built.
Recent advances in large language models (LLMs) have enabled multimodal capabilities for tasks such as image captioning and visual question answering. However, these visual language models (VLMs) still struggle with complex real-world visual reasoning that requires external knowledge - called "visual information seeking".

To address this limitation, researchers at Google have introduced a new method called AVIS, which integrates Googles PALM with computer vision, web search, and image search tools. With these tools, AVIS uses a language model in a dynamic framework to autonomously search for visual information.
Googles AVIS learns from humans
Unlike previous systems that combine large language models with tools in a rigid two-step process, AVIS uses them more flexibly for planning and reasoning. This allows actions to be adapted based on real-time feedback.
AVIS has three main components:
- A planner that determines the next action (API call and query) using the LLM
- A working memory to retain information from past API executions
- A reasoner that processes API outputs using the LLM to extract useful information
The planner and reasoner are used iteratively, with the planner deciding on the next tool and query based on the updated state from the reasoner. This continues until the reasoner determines that there is sufficient information to provide the final answer.
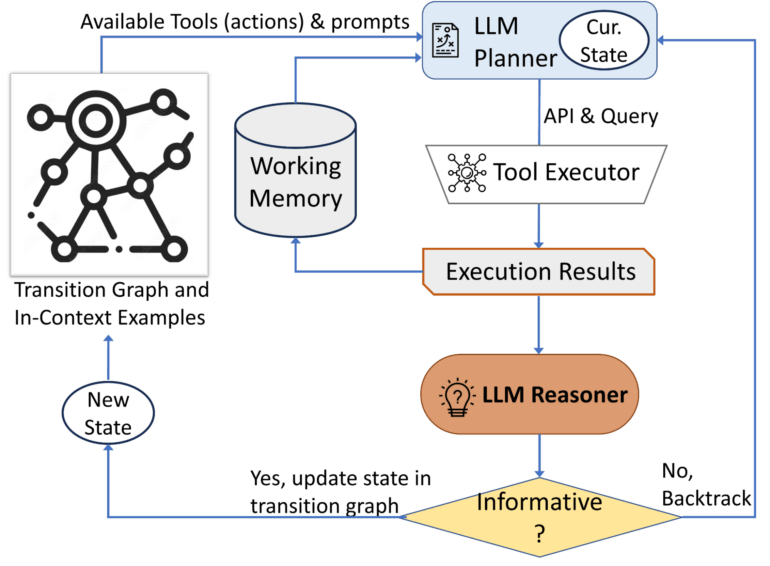
Three types of tools are also integrated:
- Computer vision tools for extracting visual information from images
- A web search tool for retrieving open-world knowledge and facts
- An image search tool to read relevant information from metadata associated with visually similar images
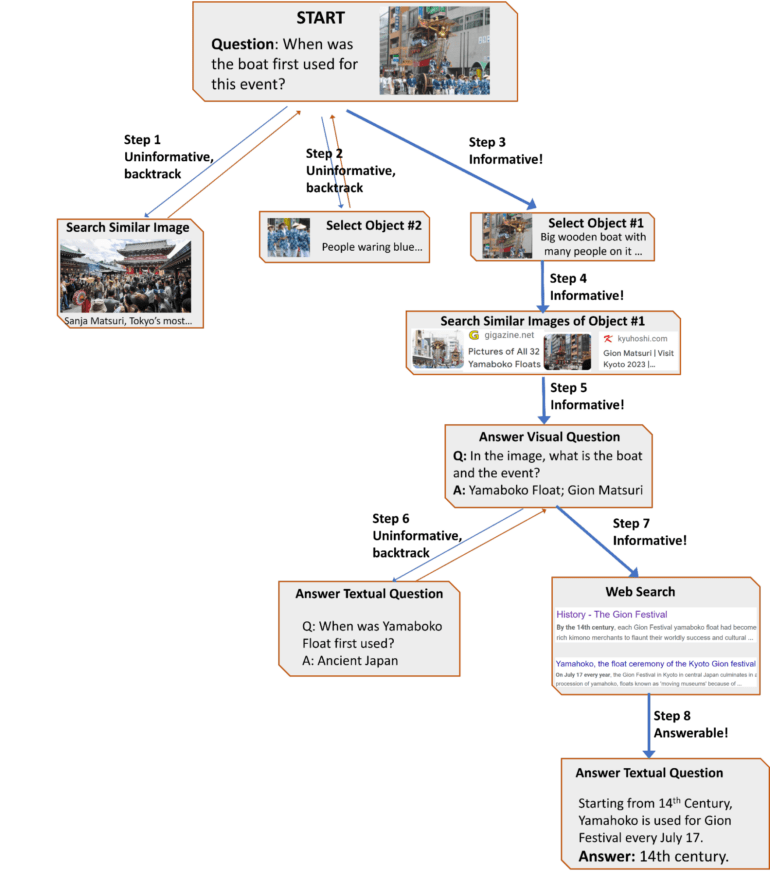
To find out how best to exploit these capabilities, the researchers conducted a user study that captured human decision-making using visual reasoning tools. The study revealed common sequences of actions that were used to construct a transition graph that guides AVIS in its behavior.
AVIS reaches state-of-the-art without fine-tuning
On the Infoseek dataset, AVIS achieved 50.7% accuracy, significantly outperforming fine-tuned visual language models such as OFA and PaLI. On the OK-VQA dataset, AVIS achieved 60.2% accuracy with few examples, outperforming most previous work and approaching fine-tuned models, Google said.

In the future, the team wants to explore their framework on other reasoning tasks and see if these capabilities can be performed by lighter language models, as the PALM model used is computationally intensive with 540 billion parameters.




