Google's DataGemma aims to ground language models in reality and curb AI hallucinations

Google has unveiled DataGemma, a set of open models designed to improve the accuracy and reliability of large-scale language models by grounding them in real-world data.
According to Google, the development of DataGemma is in response to the persistent challenge of hallucinations in LLMs, where AI models sometimes present very convincingly inaccurate information.
DataGemma uses Google's Data Commons, a publicly available knowledge graph that contains more than 240 billion global data points from verified sources such as the United Nations, the World Health Organization, and various statistical agencies.

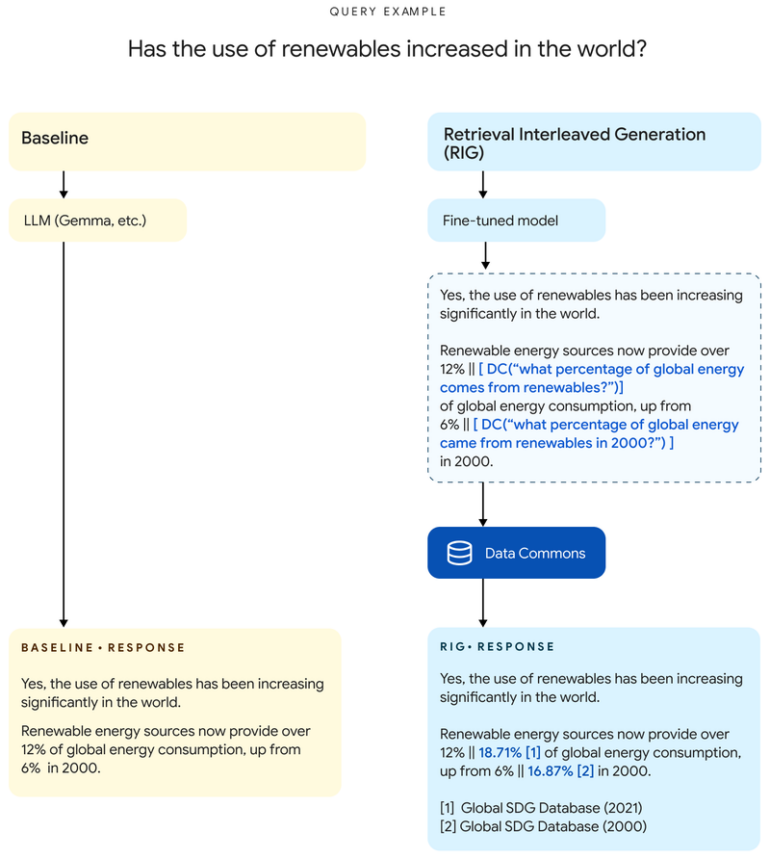
RIG recognizes and checks statistics
The models differ mainly in two well-known approaches: Retrieval Interleaved Generation (RIG) and Retrieval Augmented Generation (RAG).
RIG uses a fine-tuned Gemma-2 model to identify statistics within the responses and combines them with a retrieval from the Data Commons, allowing the model to check its output against a trusted source.
"For example, instead of saying "The population of California is 39 million," the model would output "The population of California is [DC(What is the population of California?) → '39 million']," Google explains.
RAG retrieves relevant information
In the RAG method, a Gemma model, also tuned for this use case, first analyzes the user's question and converts it into a form that Data Commons can understand. The information from this query is used to enrich the original question before a larger language model - such as Gemini 1.5 Pro, as suggested by Google - generates the final answer.
The challenge with this method is that the data returned by Data Commons can include a large number of tables spanning several years. In Google's test, entries were on average 38,000 tokens long, with a maximum of 348,000 tokens.
According to Google the implementation of RAG is only possible because of Gemini 1.5 Pro's long context window, which allows the team to augment the user query with the extensive data from the Data Commons. Gemini 1.5 Pro's context window holds up to 1.5 million tokens, the next largest of the commercially available language models would be Claude 3 with 200,000.
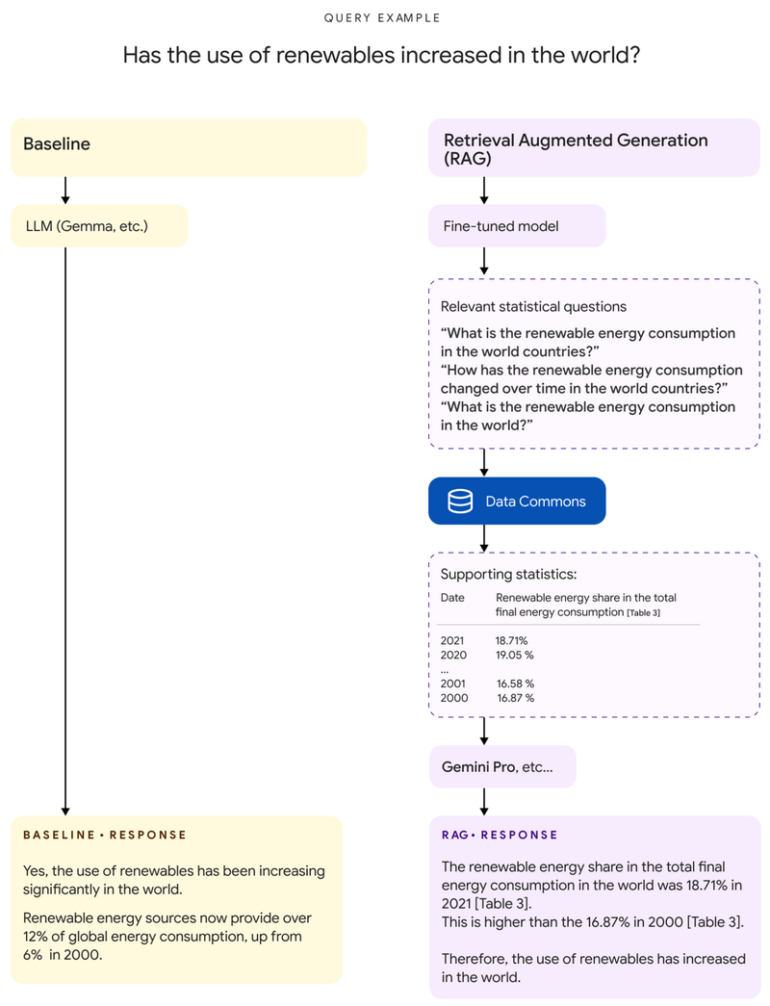
Image: Google
Both approaches have advantages and disadvantages
Both approaches have their strengths and weaknesses. According to the Google researchers, RIG works effectively in all contexts, but does not allow LLM to learn data from data commons that have been added since fine-tuning. In addition, fine-tuning requires specific datasets tailored to the task at hand.
RAG, on the other hand, automatically benefits from the ongoing development of new models, but can sometimes lead to a less intuitive user experience depending on the user prompt.
Google has made the models available for download on Hugging Face and Kaggle(RIG, RAG), along with Quickstart notebooks for both the RIG and RAG approaches.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.