Google Research presents "VideoPrism", a new visual video encoder that can be used for a variety of video understanding tasks.
According to Google, VideoPrism can be used for many tasks involving video understanding and analysis. The model excels at recognizing objects and activities in videos, finding similar videos, and, when combined with a language model, describing video content and answering questions about video.
Video: Google AI
VideoPrism is based on a Vision Transformer (ViT) architecture that allows the model to process both spatial and temporal information from video.
The team trained VideoPrism on a self-generated large and diverse dataset that includes 36 million high-quality video-text pairs and 582 million video clips with noisy or machine-generated parallel text. According to Google, this is the largest dataset of its kind.
Google says VideoPrism is unique because it uses two complementary pre-training signals: The text descriptions provide information about the appearance of the objects in the videos, while the video content provides information about the visual dynamics.
Training was done in two steps: First, the model learned to associate videos with matching text descriptions. Then it learned to predict missing parts in the videos.
In an evaluation of 33 video comprehension benchmarks, VideoPrism achieved state-of-the-art results in 30 cases - with minimal adaptation effort using a single, frozen model.
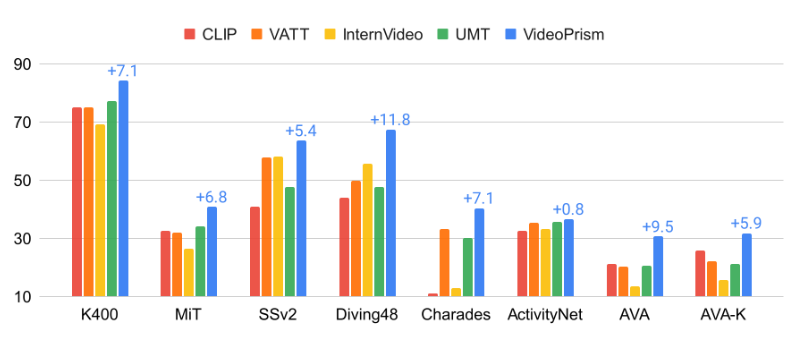
It outperformed other foundational video models in classification and localization tasks, and performed well in combination with large language models in video text retrieval, video captioning, and video question answering.

VideoPrism also performed well in scientific applications such as animal behavior analysis and ecology, outperforming models built specifically for these tasks. Google sees this as an opportunity to improve video analytics in many areas.
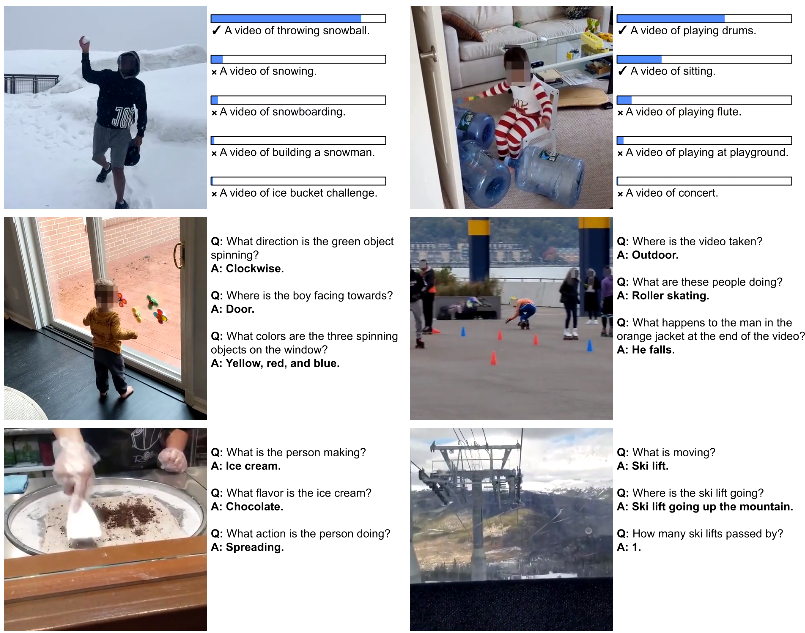
The research team hopes that VideoPrism will pave the way for further breakthroughs at the intersection of AI and video analytics, unlocking the potential of video models in areas such as scientific discovery, education, and healthcare.