GPT-5.2 tops OpenAI's new FrontierScience test but struggles with real research problems
OpenAI's new FrontierScience benchmark tests AI models at Olympiad and research levels. GPT-5.2 comes out on top, but the results also reveal where current systems still fall short.
OpenAI says existing scientific benchmarks are running out of headroom. When the company released GPQA—a "Google-proof" multiple-choice test for PhD-level science questions—in November 2023, GPT-4 scored 39 percent. Two years later, GPT-5.2 hits 92 percent. That rapid improvement, the company says, calls for tougher evaluation methods.
Enter FrontierScience, a two-part benchmark: an Olympiad set with problems at the level of international science competitions, and a research set with open-ended PhD-level challenges. The published Gold set contains 160 questions on physics, chemistry, and biology, filtered down from over 700 original problems. OpenAI is holding back the rest to check for potential contamination.
Olympic medalists and researchers designed the questions
The 100 Olympiad questions were created by 42 former international medalists or national coaches who have collectively won 108 Olympic medals. The problems draw from the International Physics Olympiad, International Chemistry Olympiad, and International Biology Olympiad. Every answer can be verified as a single number, algebraic expression, or unique term.
The 60 research questions come from 45 scientists with expertise spanning quantum mechanics, molecular biology, and photochemistry. OpenAI says each task should take at least three to five hours to solve. Instead of a single correct answer, research tasks are scored on a ten-point rubric, with GPT-5 handling the automated grading at high reasoning intensity.
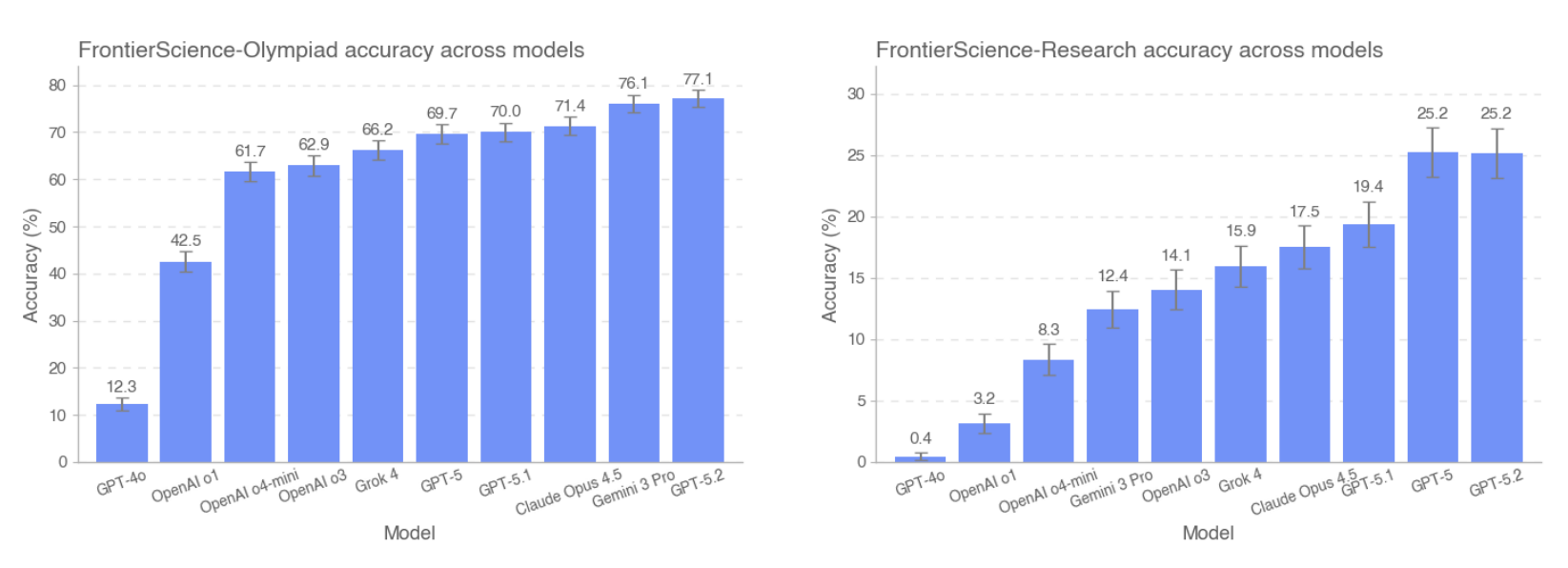
GPT-5.2 leads, but research tasks remain tough
All reasoning models were tested at "high" reasoning intensity, with GPT-5.2 also tested at "xhigh" - and without browsing enabled. GPT-5.2 scores 77 percent on the Olympiad set and 25 percent on Research. Gemini 3 Pro trails close behind on Olympiad at 76 percent. On Research, GPT-5.2 and GPT-5 tie for first place, and in a "surprising" (OpenAI) twist, GPT-5 significantly outperforms the newer GPT-5.1, which manages just about 19 percent.
Claude Opus 4.5 hits 71 percent on Olympiad and 18 percent on Research. Grok 4 scores 66.2 percent and 16 percent respectively. The older GPT-4o lags far behind at 12 percent on Olympiad and under one percent on Research. OpenAI's first reasoning model o1, released last September, marked a major leap forward.
More compute means better results
Performance scales with compute time. GPT-5.2 jumps from 67.5 percent at low reasoning intensity to 77 percent at the highest setting on the Olympiad set. On Research, scores climb from 18 to 25 percent. OpenAI's o3 model bucks the trend on Research: it actually does slightly worse at high reasoning intensity than at medium. The company calls this "surprising" but doesn't explain why.
OpenAI says the results show real progress on expert-level questions but leave plenty of room for improvement, especially on open research tasks. Across subjects, models do best in chemistry. Common failure modes include logic errors, trouble with niche concepts, calculation mistakes, and factual errors.
Language models are getting better at working with numbers
Recent months have brought multiple reports of AI speeding up research. OpenAI released "GPT-5 Science Acceleration," a collection of case studies showing mathematicians getting help with proofs, physicists with symmetry analysis, and immunologists with hypotheses and experimental design.
Physicist Steve Hsu published a paper whose central idea came from GPT-5. He sees this as the start of "hybrid human-AI collaborations" that could become standard in math, physics, and other formal sciences. The result has also drawn criticism.
OpenAI has announced plans to build autonomous research agents by 2028 that could fundamentally speed up scientific discovery. Google DeepMind and OpenAI also showed in 2025 that AI models with advanced reasoning and reinforcement learning can increasingly solve complex math problems on their own for hours without symbolic aids. Mathematician Terence Tao has said AI helped him solve problems too.
At the same time, experts warn of risks: uncritical use of AI in science could churn out large volumes of plausible-sounding but wrong results.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.