Nvidia CEO Jenson Huang shows off the first Hopper GPU, new AI models and an Omniverse computer.
This year's GTC also starts with a detailed presentation by Nvidia's CEO Jensen Huang. This time, Huang gives his review and outlook on AI hardware and software and the Omniverse against a black, digital backdrop - the kitchen seems to have had its day. I have summarized the most important news of GTC 2022 for you.
Hopper GPU for AI development is inbound
One of the most significant announcements is the unveiling of the new Hopper GPU H100. Built for AI computations, the GPU is the direct successor to Nvidia's A100 and relies on TSMC's 4N process and HBM3 memory. The H100 GPU includes 80 billion transistors, delivers 4.9 terabytes of bandwidth per second and relies on PCI Express Gen5.
The new GPU is said to execute current AI models up to 30 times faster than its predecessor. For AI training, the H100 GPU is about three times faster than the A100 GPU according to Nvidia. For FP32, the H100 GPU delivers 1,000 TeraFLOP of performance, and for FP16, 2,000 TeraFLOP.

Thanks to a new Transformer Engine, in which the fourth-generation Tensor cores dynamically switch between FP8 and FP16 precision with specialized software, large language models in particular are supposed to be trained much faster.
For example, GPT-3 can be trained six times faster and a mixture-of-experts model up to nine times faster. The GPU also supports DGX Instructions, a method with which dynamic programming tasks, for example for the Traveling-Salesman problem, can be accelerated by a factor of seven.
Hopper GPUs coming for single cards and superpods
Like the A100, the H100 GPUs will be installed as single cards, in HGX/DGX systems, in pods and in superpods. The H100 CNX delivers an H100 GPU with a fast data link for servers, and the HGX/DGX-H100 system consists of eight H100 GPUs with 640 gigabytes of HBM3 memory with 24 petabytes per second of memory bandwidth. According to Huang, up to 32 HGX/DGX-H100 systems can be interconnected as DGX pods with NVLink switch.
One such DGX pod, he said, delivers ExaFLOP AI processing power and 20.5 terabytes of HDM3 memory with a memory bandwidth of 768 terabytes per second, thanks to 256 H100 GPUs. The entire Internet - as an example - has a current throughput of just under 100 terabytes per second, the Nvidia CEO said.
Larger systems with hundreds of DGX-H100 systems are also possible. Huang announced the first so-called superpod under the name "Nvidia Eos." The supercomputer comprises 576 DGX-H100 systems with a total of 4,608 H100 GPUs and should be ready in a few months. Nvidia expects the Eos to be the world's fastest AI supercomputer.
Nvidia CPU makes headway, AI framework gets a boost
The Grace CPU, announced last year and being developed specifically for data centers, is well on its way, Huang said. Grace is expected to be available next year and will enable transfer rates between CPU and GPU of 900 gigabytes per second thanks to a direct chip-to-chip connection.
Nvidia also showed a Grace superchip that connects two Grace CPUs. The superchip comes with 144 CPU cores and one terabyte per second of memory bandwidth. Nvidia expects the CPU to leave other products in the data center market far behind regarding performance and energy efficiency.
Besides hardware for AI computation, there were numerous announcements at the GTC keynote for improved AI frameworks and new models. For example, Nvidia's Riva 2.0 speech framework is now available, and the Maxine video and conferencing framework is getting improvements to existing modules and new features designed to improve audio quality.
A new framework called Sionna is designed to support 6G research with AI, and a new version of the Merlin recommendation algorithm framework is freely available to all. Huang also announced AWS support for the Nemo Megatron training framework in the coming months.
Omniverse and the second wave of AI
Huang kicked off his keynote with an introduction to Nvidia's Omniverse, which is set to become a platform for the second wave of artificial intelligence. Frameworks such as PyTorch and TensorFlow are the basis of the first wave, which includes computer vision and speech processing. The second wave includes robotics, for example, in which AI agents plan and act.
The Omniverse enables digital twins, which are used for creative collaboration or digital replication of factories, for instance, and which are also the basis for training robots and autonomous cars, according to Nvidia.
For the latter, Nvidia showed two current training methods that use neural rendering to create digital worlds from recorded trips, which are then used for AI training for autonomous cars. The trained models can then be run on Nvidia's Orin computer in real vehicles. The Chinese electric car manufacturer BYD uses the Orin hardware in its vehicles.
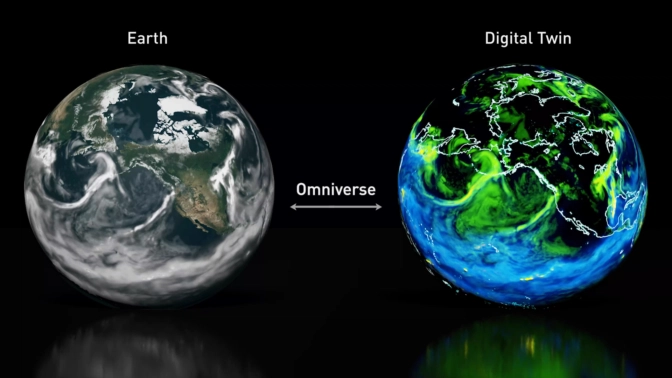
As if that wasn't enough, the Omniverse is also expected to help the climate. Huang announced a digital twin platform for science, consisting of the Modulus AI framework for physics models and the Omniverse Earth-2 simulation.
As an example of the potential, Nvidia showed the "FourCastNet" prediction model trained with 10 terabytes of Earth data such as 40 years of weather forecasts. Nvidia said the model emulates and predicts the behavior and risks of extreme weather events such as hurricanes with greater reliability and up to 45,000 times faster than classical approaches.
Omniverse computers and cloud access
The Omniverse is also getting new tools such as an AI-assisted search for 3D assets, new developer tools, and an avatar module. As of now, the Omniverse with all associated tools is also available in the cloud via Geforce Now. According to Nvidia, the software has been downloaded 150,000 times so far. With cloud access, the company wants to lower the hardware entry barrier.
However, unlike AI calculations or other high-performance computing tasks, digital twins and the Omniverse require physically accurate real-time simulations. Data centers for the Omniverse would therefore need scalability, low latency and precise time processing - what Huang calls a synchronous data center.
Nvidia is therefore introducing Nvidia OVX, a computing system designed to run large-scale digital twins. An OVX server relies on eight Nvidia A40 GPUs, an OVX Superpod on 32 OVX servers.
According to Nvidia, OVX systems combine high-performance GPU-accelerated compute, graphics and AI performance with high-speed memory access, low-latency networking and precise timing. OVX is expected to be enhanced in the near future by the Spectrum-4 Ethernet platform, also announced, which will enable switching throughput of 51.2 terabits per second.
More information is available on Nvidia's blog post about the Hopper announcement. You can watch the complete keynote in the following video.