Laion's new dataset shows how AI can help with AI training

A new dataset from Laion shows how AI can help with AI training and improve the performance of future generative AI systems.
Popular image AI systems such as DALL-E 2, Stable Diffusion, and Midjourney can generate images based on text. They gain this capability by training with text-image pairs from the web.
However, many web images are poorly, incompletely, or not labeled at all. If these images were more detailed and correctly labeled, future image AI systems could better understand topics and generate images that more closely match the text.
AI helps with image description
This is where the new LAION-COCO dataset from research organization Laion comes in. Laion specializes in compiling large datasets for AI training.
Well-known, for example, is the Laion5B dataset, which is used, among other things, for training Stable Diffusion. The dataset is sometimes criticized because the more than five billion linked images include images that are not intended for AI training.
For LAION-COCO, Laion generated additional image labels for 600 million of the images linked in Laion5B. Laion used a combination of BLIP L/14 and 2 CLIP versions (L/14 and RN50x64) for text generation. BLIP L/14 generated 40 captions, CLIP Open AI L/14 selected the best 5 of them, among which the RN50x64 model then determined the best caption.
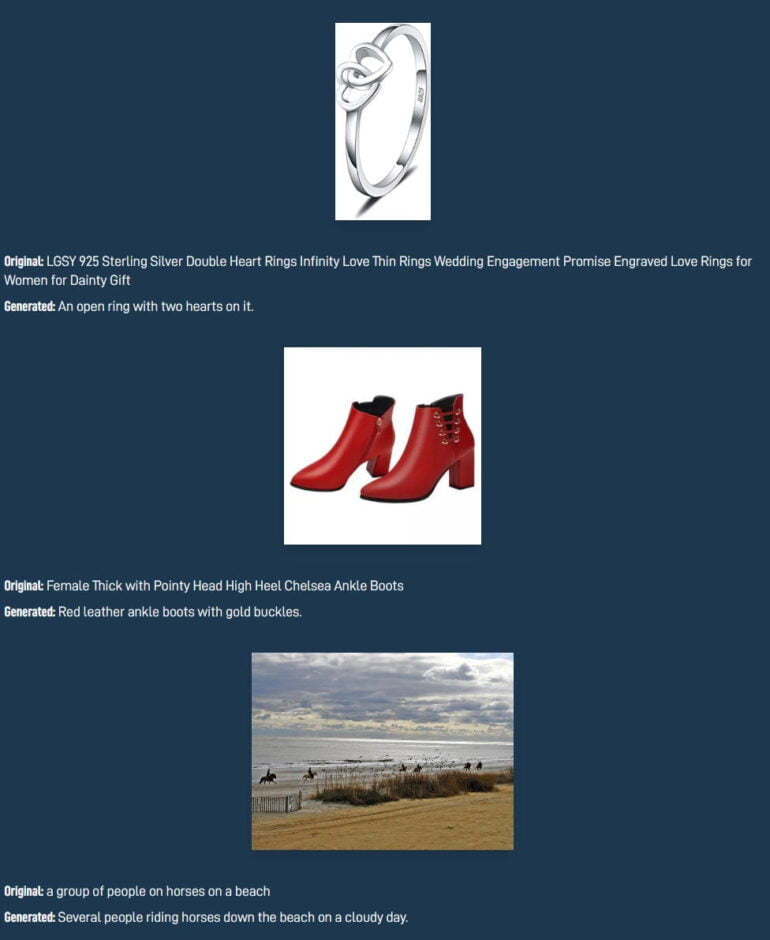
The dataset is intended to help research whether synthetically generated captions can complement captions written by humans, Laion writes. Models trained with the dataset could show the value of generated captions.
Machine labels and human ones are indistinguishable
In an initial evaluation, Laion had human testers rate 200 images, 100 captioned by humans and 100 machine-generated.
In 47.5 percent of all cases, the testers agreed that captions that were actually written by machines were written by humans. "This makes us confident that our captains are on average pretty good," Laion writes.
In post-evaluation discussions, testers stated that, aside from obvious errors, it had been very difficult to distinguish human and machine captions. Laion attributes these obvious errors (see images below) to a lack of concepts for what is happening in the picture and "because it's knowledge is not grounded in a sufficiently sophisticated world model."

The free download of LAION-COCO is available at Huggingface. The dataset consists of parquet files. The columns contain the original caption, the URL to the image, the top caption, and a list of alternative captions with lower CLIP scores.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.