Language models use a "probabilistic version of genuine reasoning"
A recent study conducted by researchers from Princeton University and Yale University has shed light on the key factors that impact the performance of large language models (LLMs) when solving tasks using chain-of-thought (CoT) prompts.
CoT prompts encourage LLMs to generate a series of intermediate steps before providing the final answer, and are a crucial element of OpenAI's latest o1 model.
The research team focused their case study on the symbolic reasoning task of decoding shift ciphers, where each letter of the original text is shifted a certain number of places in the alphabet. By concentrating on this relatively simple task, they identified three factors that systematically influence CoT performance: probability, memorization, and noisy reasoning.
The researchers demonstrated that the likelihood of the expected task outcome, what the model implicitly learned during pre-training, and the number of intermediate steps involved in reasoning can significantly affect the accuracy of the three LLMs studied: GPT-4, Claude 3, and Llama 3.1.
To test their observations, the team employed logistic regression, a statistical method, to investigate how various factors influence the probability of GPT-4 providing the correct answer to an example. They considered factors such as the likelihood of the encrypted input text, the likelihood of the correct decrypted text, the frequency of the respective shift in real texts, and the minimum number of steps required to decode each letter.
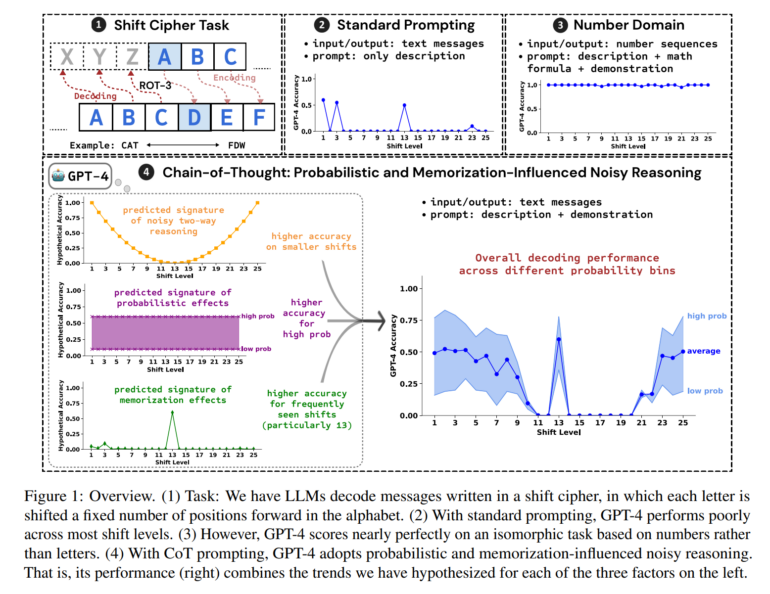
The results revealed that the probability of decoded text, the frequency of shifting, and the number of steps required all had a statistically significant impact on GPT-4's performance. This supports the hypothesis that GPT-4 utilizes probabilities, memorization, and a form of "noisy reasoning".
The importance of intermediate steps
The study also highlighted the critical role of the intermediate steps generated by GPT-4 in its chain of thought. These steps provide essential context on which the model relies when generating the final results. Interestingly, the correctness of the content in the example chain was found to be less important than the model adopting the format to generate its own correct chain.
The researchers concluded that performance on CoT prompts reflects both memorization and a probabilistic version of genuine reasoning, indicating that the model can draw logical conclusions but is also influenced by probabilities, rather than relying solely on symbolic reasoning.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.