
New research shows that large language models (LLMs) can improve themselves when fine-tuned with their own inferences.
Large language models can usually solve many tasks, but only a few of them are inherently highly complex. So-called fine-tuning helps to adapt large language models for specific tasks. Selected, specific data is compiled for this post-training.
With this approach, specialized language systems can be abstracted from a large language model, which is much less resource-intensive than the actual training of the language model. However, some manual effort is still required, e.g., for the preparation of the data.
Large language models can improve themselves with their own answers
Researchers at the University of Illinois at Urbana-Champaign and Google now show that large language models can use chain-of-thought prompting to self-generate training data for post-training and draw correct conclusions more frequently after training with this data.
To do so, the research team had Google's large language model PaLM generate answers to a series of questions as chains of thought. In the next step, the researchers filtered out the most consistent answers, which are not necessarily the correct ones, using the majority voting method. They used the responses filtered in this way as data for fine-tuning the model. The researchers call this approach "self-consistency.
This is similar to how a human brain sometimes learns: given a question, think multiple times to derive different possible results, conclude on how the question should be solved, and
then learn from or memorize its own solution.Excerpt from the paper
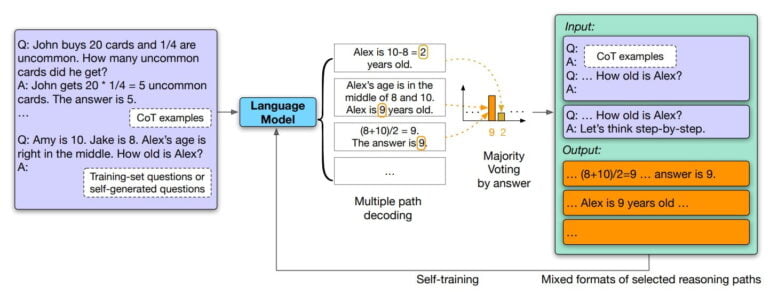
The researchers estimate that the possible influence of incorrect answers in fine-tuning is small: If an answer has more consistent chains of thought, it is more likely to be correct. Conversely, incorrect answers would likely have few consistent chains of thought and therefore would not have a significant impact on a model's performance in fine-tuning.
Self-improved language model achieves new highs in benchmarks
In six machine inference benchmarks, the language model fine-tuned with self-generated inferences achieves improvements between 1.1 and 7.7 percent. It achieves new top scores in the ARC, OpenBookQA, and ANLI benchmarks.
The performance improvement of the language model with self-generated unlabeled datasets shows that the systems can achieve better performance without fundamental changes to the architecture - and with a relatively simple approach. In a next step, the researchers plan to combine self-generated with labeled data to further improve the performance of LLMs.
Another example of the optimization potential of large language models is Deepmind's Mind's Eye. Here, data from a physics simulator helps the language model draw better logical conclusions for physics questions. Rather than fine-tuning with additional data, Deepmind takes a hybrid approach in this case by outsourcing specialized knowledge to an external expert system.




