
Google combines language models with a physics simulator. The hybrid AI system scores new bests in physical reasoning benchmarks.
Large language models like OpenAI's GPT-3 or Google's PaLM cannot reason reliably. This is a central fact in the debate about the role of Deep Learning on the way to more general forms of artificial intelligence.
Methods like chain-of-thought prompting, more training data and larger models like PaLM led to better results in benchmarks, but not to a fundamental breakthrough.
Researchers are therefore experimenting with hybrid approaches that use the language capabilities of AI models to issue queries to specialized, external libraries or systems.
OpenAI's WebGPT was an early example of this. More recently, AI researcher Sergey Karayev has connected GPT-3 to a Python interpreter that can perform exact mathematical calculations or make API requests.
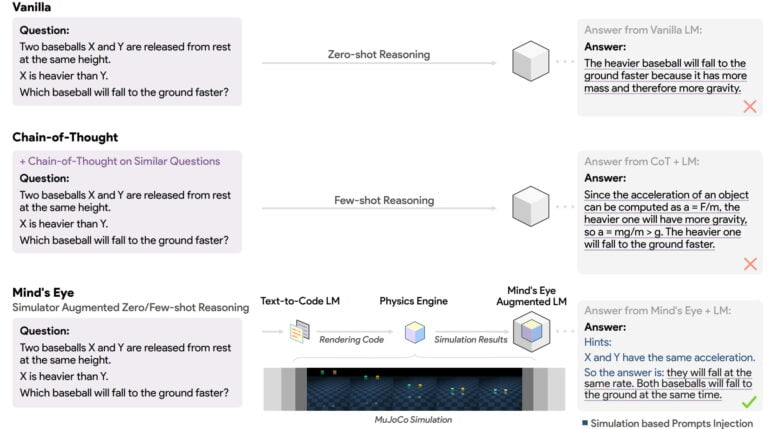
Google links PaLM with MuJoCo simulator
Researchers at Google are now going a step further by linking large language models to a physics simulator. Because current language models are trained exclusively with written text, they lack the grounded experience of humans in the real world, the team writes.
The resulting inability to relate language to the physical world leads to knowledge being misrepresented, which in turn leads to obvious errors in reasoning.

To ground language models in the physical world, the researchers propose to send text prompts from a language model to a MuJoCo physics simulation and then use the results as part of the input to the language model. The team calls this paradigm "Mind's Eye" and is testing it with the UTOPIA physical reasoning benchmark developed for this purpose.
Mind's Eye: text to code to simulation
Mind's Eye consists of three modules: The language model passes questions whose answers require physical reasoning to a text-to-code language model trained with 200,000 text-code pairs in the style of the UTOPIA benchmark.

The generated code is passed to MuJoCo, where it is executed. The result is then converted into text. Finally, this text is transferred to the input window of the language model and serves as input for the final response of the model.
Using this method, Google researchers achieve massive leaps in performance: Google's PaLM 540B achieves 92.5 percent instead of 39.4 percent in UTOPIA with Mind's Eye, and OpenAI's InstructGPT achieves 99.1 percent instead of 68.6 percent. On average, the accuracy of the tested language models increases by 27.9 in zero-shot and 46 percent in the few-shot scenario.
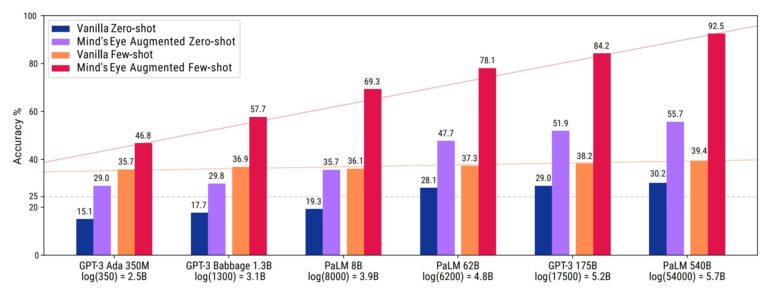
Google's Mind's Eye expands the possibilities of language models
In addition to the scalability of the approach and the simulation-based reasoning, Mind's Eye is also very efficient: Since the method delegates domain-specific knowledge to external expert modules (in this case MuJoCo), this knowledge is decoupled from the reasoning capability.
The size of the required language model can thus be significantly reduced - the network does not need to remember domain-specific knowledge. In practice, the team was able to show that smaller models with Mind's Eye achieve the performance of models 100 times larger in the UTOPIA benchmark.
We conclude that Mind’s Eye is not only effective and scalable but also efficient, as it is able to boost the reasoning performance of small-scale LMs significantly, requiring neither handcrafted prompts nor costly fine-tuning.
Mind's Eye Paper
The team believes that the idea of relying on a simulation pipeline for reasoning can easily be extended to other areas - especially where simulations already exist. For example, economic change or thermodynamics simulations could be used.
"The dynamic nature of Mind’s Eye where we generate grounding evidence unlocks the scaling potential of these models," the paper states.
In other words, the potential of large AI models is not yet exhausted, and techniques like Mind's Eye can unlock new capabilities without requiring fundamentally new AI technologies.



