LongWriter: Current LLMs can generate much longer text than previously thought

Researchers have developed a method to extend the output length of AI language models to over 10,000 words. Until now, a limit of 2,000 words was common.
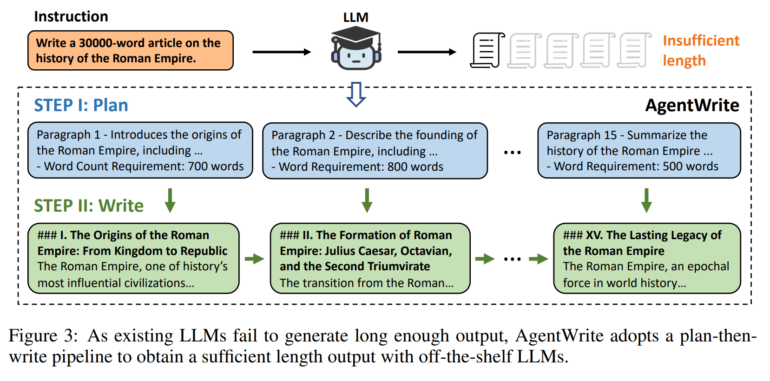
Today's language models can process inputs of hundreds of thousands or even millions of tokens, but without external intervention, they do not generate outputs longer than a modest 2,000 words.
According to a new study, this is primarily due to the training data. Through controlled experiments, the researchers found that a model's effective output length is limited by the longest output it has seen during supervised fine-tuning (SFT).
In other words, the output limitation is due to the scarcity of examples with long outputs in existing SFT datasets. To solve this problem, the scientists introduce "AgentWrite" - an agent-based pipeline that breaks down long generation tasks into subtasks. This allows existing LLMs to generate coherent outputs of over 20,000 words.
LongWriter routinely generates 40 pages of text
Using AgentWrite, the researchers created the "LongWriter-6k" dataset. It contains 6,000 SFT data with output lengths between 2,000 and 32,000 words. By training with this dataset, they were able to scale the output length of existing models to over 10,000 words without compromising output quality.
Video: Bai, Zhang et al.
To evaluate ultra-long generation capabilities, they also developed "LongBench-Write" - a comprehensive benchmark with various writing instructions and output lengths ranging from 0 to over 4,000 words.
The researchers' 9 billion parameter model, further enhanced by Direct Preference Optimization (DPO), achieved top performance in this benchmark. It even surpassed much larger proprietary models.
The code and model for LongWriter are available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.