Meta has released a new version of data2vec: data2vec 2.0.
Update Dec. 29, 2022:
Meta's upgraded learning algorithm for different modalities is significantly faster than its predecessor.
Nearly eleven months after the release of data2vec, Meta's AI division is showing off an improved version of its multimodal learning algorithm. With data2vec, it is much easier to transfer advances in one area of AI research, such as text understanding, to other areas such as image segmentation or translation, Meta says. Like its predecessor, data2vec 2.0 can process speech, images and text, but it learns much faster.
Data2vec 2.0 is much more efficient and exceeds the strong performance of the first version, the company said. It achieves about the same accuracy as a widely used computer vision algorithm but is 16 times faster.
Data2vec 2.0 learns contextualized representations
Similar to its predecessor, data2vec 2.0 predicts contextualized representations of data instead of just the pixels in an image, words in a passage of text, or the sound in a voice file.
Specifically, the algorithm learns the word bank, for example, based on the complete sentence in which that word occurs, and thus learns to represent the correct meaning of the word more quickly - i.e., as a financial institution.
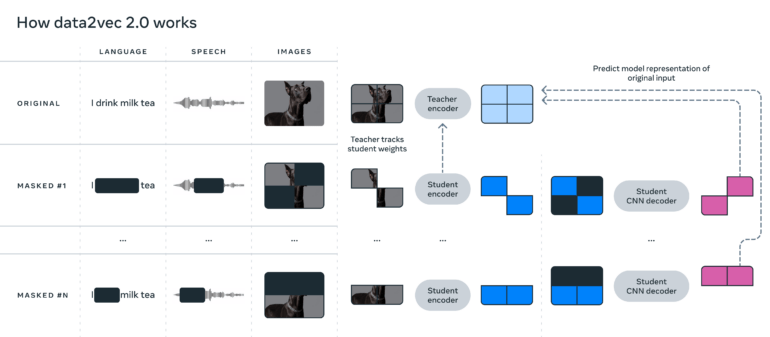
Meta suspects that this contextualization is responsible for the algorithm's fast learning performance. To increase efficiency, the team also relies on student nets learning from a teacher net and a CNN rather than a transformer decoder.
Meta hopes that more efficient algorithms like data2vec 2.0 will lead to machines that can understand extremely complex data like the content of an entire movie.
Examples and code are available on Github.

Original article from January 22, 2022:
Meta presents a learning algorithm that enables self-supervised learning for different modalities and tasks.
Most AI systems still learn supervised with labeled data. But the successes of self-supervised learning in large-scale language models such as GPT-3 and, more recently, image analysis systems such as Meta's SEER or Google's Vision Transformer, clearly show that AIs that autonomously learn the structures of languages or images are more flexible and powerful.
However, until now, researchers still need different training regimes for different modalities, which are not compatible with each other: GPT-3 completes sentences in training, a vision transformer segments images, and a speech recognition system predicts missing sounds. All AI systems, therefore, work with different types of data, sometimes pixels, sometimes words, and sometimes audio waveform. This discrepancy means that research advances for one type of algorithm do not automatically transfer to another.
Metas data2vec processes different modalities
Researchers at Metas AI Research are now introducing a single learning algorithm that can be used to train an AI system with images, text, or spoken language. The algorithm is called "data2vec," a reference to the word2vec algorithm, which was a foundation for developing large-scale language models. Data2vec combines the training process of the three modalities and achieves in benchmarks the performance of existing alternatives for individual modalities.
Data2vec circumvents the need for different training regimes for different modalities with two networks that work together. The so-called Teacher network first computes an internal representation of, say, a dog image. Internal representations consist of, among other things, the weights in the neural network. Then, the researchers mask a part of the dog image and let the Student network compute an internal representation of the image as well.
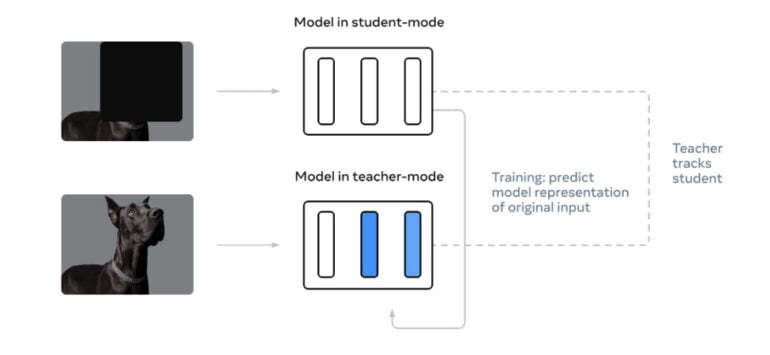
However, the Student network must predict the representation of the full image. But instead of learning with more images, like the Vision Transformer, the Student network learns to predict the representations of the Teacher network instead.
Since the latter was able to process the complete image, with numerous further training passes the Student network learns better and better to predict the Teacher representations and thus the complete images.
Since the Student network does not directly predict the pixels in the image, but instead the representations of the Teacher network, from which pixels can then be reconstructed, the same method works for other data such as speech or text. This intermediate step of representation predictions makes Data2vec suitable for all modalities.
Data2vec aims to help AI learn more generally
At its core, the researchers are interested in learning more generally: AI should be able to learn many different tasks, even those that are completely foreign to it. We want a machine to not only recognize the animals shown in its training data, but also to be able to adapt to new creatures if we tell it what they look like, Meta's team said. The researchers are following the vision of Meta's AI chief Yann LeCun, who in spring 2021 called self-supervised learning the "dark matter of intelligence."
Meta is not alone in its efforts to enable self-supervised learning for multiple modalities. In March 2021, Deepmind released Perceiver, a Transformer model that can process images, audio, video and cloud-point data. However, that has yet been trained in a supervised fashion.
Then, in August 2021, Deepmind introduced Perceiver IO, an improved variant that generates a variety of results from different input data, making it suitable for use in speech processing, image analysis, or understanding multimodal data such as video. However, Perceiver IO still uses different training regimes for different modalities.
Meta's researchers are now planning further improvements and may look to combine the data2vec learning method with Deepmind's Perceiver IO. Pre-trained models of data2vec are available on Meta's Github.
Read more about Artificial Intelligence:
- Truly intelligent AI - three things Google's AI chief says are missing
- Moffet AI: AI chip startup receives million-dollar investment
- History of robots: from Heron to Spot to the AI future




