
Meta releases a new AI model capable of directly translating speech in 35 languages and text in 100 languages.
With the new multimodal encoder-decoder model "SeamlessM4T", Meta combines technologies from its long-standing AI translation projects No Language Left Behind (NLLB), Universal Speech Translator and Massively Multilingual Speech into a single model. M4T stands for Massively Multilingual & Multimodal Machine Translation.
According to Meta, by implementing the various previous models in one system, it reduces errors and delays, improving the efficiency and quality of the translation process.
The model is multimodal in that it can translate text into 100 languages in addition to spoken language, which is audio in 35 languages. In total, the model can translate speech-to-text, speech-to-speech, text-to-speech, and text-to-text, as well as automatically recognize speech.
According to Meta, SeamlessM4T is the first model that can translate many languages (35) directly back into spoken language without going through the detour of text translation. The model is supposed to be a "significant step" on the way to a universal translator like the Babel fish in The Hitchhiker's Guide to the Galaxy, which Meta explicitly mentions as a goal in the announcement.
Video: Meta
AI could help Meta to overcome language barriers on its social platforms
According to Meta, SeamlessM4T achieves new state-of-the-art results on major translation benchmarks, outperforming OpenAI's Whisper. If you want to see for yourself, you can try an interactive demo here.
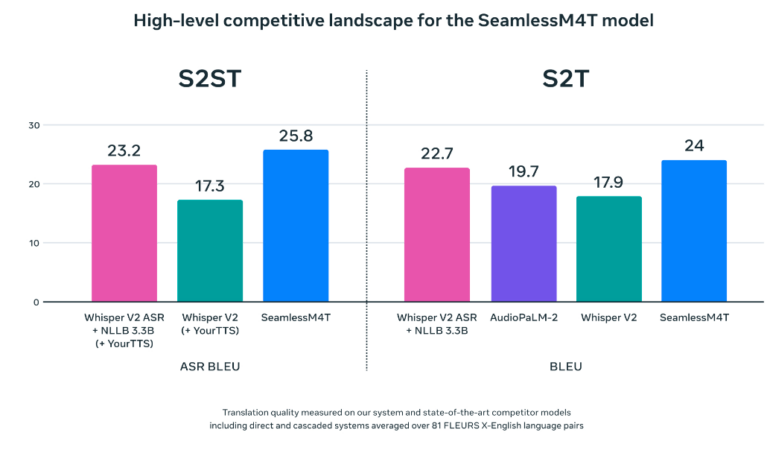
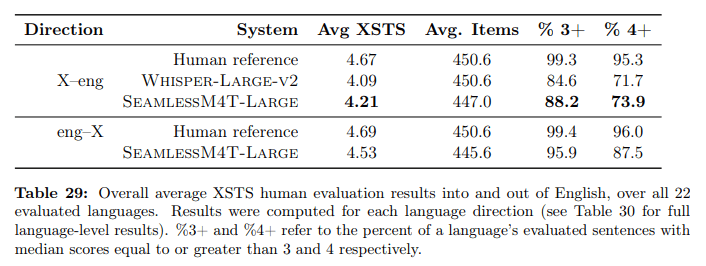
The largest model, SeamlessM4T-Large, is also ahead of Whisper in human evaluation, but the gap is smaller than in the automatic benchmarks. Both models still lag human translations in terms of quality, but the gap narrows with each new model.
Meta is releasing the model under the CC BY-NC 4.0 license as an open-source model on Github, but you cannot use it commercially. According to Meta CEO Mark Zuckerberg, it will be integrated into the company's own social platforms Facebook, Instagram, WhatsApp, Messenger and Threads in the future.

In addition to the model, Meta is also releasing the "SeamlessAlign" dataset that the team compiled to train SeamlessM4T. Meta says it is the largest open dataset for multimodal translation, with 470,000 hours of material for 37 languages. Expansion to 100 languages is a topic for future development. This would be the next step towards a universal translator.



