Meta's chief AI scientist Yann LeCun unveils Meta's plans for an AI that will learn and think like animals and humans.
In January, Meta's chief AI scientist Yann LeCun spoke with podcaster Lex Fridman about the current state of artificial intelligence and the three major challenges on the road to the next generation of AI. Current AI systems are still far behind the cognitive abilities of, say, a cat, despite many billions of parameters, the Turing Prize winner said.
LeCun sees the reason for this lead of biological intelligence primarily in its highly developed understanding of the world. This understanding is based on abstract representations of the environment, which gives humans and animals the ability to form models that predict actions and their consequences. The ability to learn such models of the environment is therefore central to the next generation of AI.
LeCun fleshes out the architecture of autonomous AI
In a blog post, Meta now presents new details about LeCun's vision, including a glimpse of a possible architecture of an "autonomous" artificial intelligence. This perceives its environment, plans accordingly and executes actions.
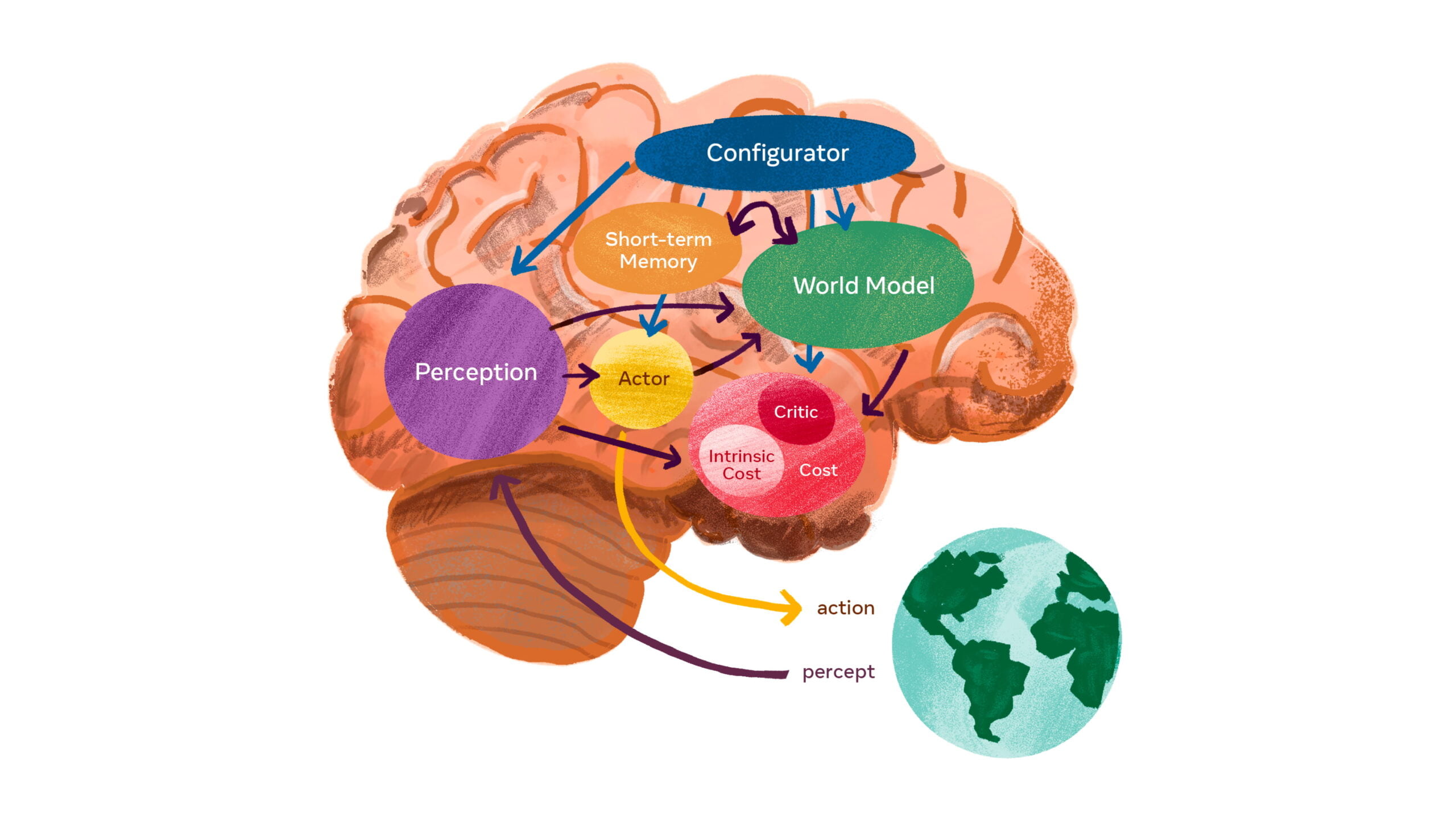
The architecture is composed of six modules:
- The configurator module configures the other modules for the desired task. For example, it could adjust the parameters of the other modules.
- The perception module processes sensor signals and is thus supposed to assess the current state of the world. Since only a subset of the available sensor information is relevant for certain tasks, the configurator module must adapt the perception module accordingly to extract the required information.
- The world model module has two tasks: It must provide information about the state of the world that is necessary to solve the task and that the perceptual module does not provide, and it must predict plausible future states of the world. Thus, the world model should serve as a kind of simulator for the relevant parts of the world. It is the most complex part of the architecture.
- The cost module calculates the costs the AI faces for certain planned actions, e.g., damage to a robot, energy consumption, or violations of certain behavioral rules. The AI's goal is to keep costs as low as possible. According to LeCun, the module provides the basic behavioral drives and intrinsic motivations.
- The actor module computes proposals for actions and searches for an optimal sequence that minimizes estimated costs. The result is an optimal sequence of actions that accomplishes the task and keeps costs low.
- The short-term memory module stores the current and predicted state of the world and the associated costs.
Each module is intended to be compatible with gradient-based learning - the method that enables current Deep Learning.
World model through abstractions of abstractions
At the heart of the architecture presented is the world model module, which is designed to predict the world based on information from the perception module. Where is a perceived person moving? Does a car turn - or does it continue straight ahead?
However, the real world is only partially predictable. Every situation can take numerous forms, and many perceived details are irrelevant to the task at hand. For example, an autonomous car does not need to know where hundreds of leaves on a tree are moving, but it does need to know where the surrounding cars are moving.
The world model must therefore learn abstract representations of the world that preserve important details and ignore unimportant details. Then it must provide predictions at the level of abstraction appropriate to the task.

LeCun suggests that so-called "Joint Embedding Predictive Architecture (JEPA)" can help solve this challenge. JEPA enables unsupervised learning with large amounts of complex data while generating abstract representations.
At its core, JEPA learns the dependencies between two inputs, x and y, such as a video clip and subsequent images. New learning methods combined with JEPA enable training with high-dimensional data sets such as videos, according to Meta.
A major advantage of JEPA is that the method allows multiple modules to be layered on top of each other, making predictions at a higher level of abstraction based on the prediction of lower-level modules. For example, the scenario "A cook prepares crepes" can be described at several abstraction levels.
- At a high level of abstraction, the cook mixes flour, milk, eggs, ladles the batter into the pan, lets the batter fry, turns it over, and frys again.
- At a lower level, "scoops the batter into the pan" means the cook scoops some batter and spreads it in the pan.
Thus, abstract descriptions can be broken down to lower and lower levels, down to precise hand movements from millisecond to millisecond. At this low level, the world model is intended to make short-term predictions, while at higher levels of abstraction it makes long-term predictions.
World model should bring AI closer to human intelligence
Should the hierarchical JEPA structure allow for a sufficiently comprehensive world model, this could help an AI agent plan complex actions hierarchically, breaking down complex tasks into less complex and abstract subtasks. At the lowest level, these actions could then control the effectors of a robot, for example.
LeCun's higher-level vision leaves many questions unanswered, such as details about the architecture and training method of the world model. Meta therefore also describes the training of the world model as the essential challenge for real progress in AI research in the coming decades. Other aspects of the architecture also need to be defined more precisely, Meta says.
Developing machines that learn and understand as efficiently as humans is a long-term scientific endeavor with no guarantee of success, according to Meta. However, the basic research presented here will continue to lead to a deeper understanding of mind and machine and to AI advances that will benefit artificial intelligence and, in turn, mankind.





