Meta's Code "World Model" aims to close the gap between code generation and code understanding

Meta's Code World Model (CWM) is designed not just to generate code but to understand how that code runs on a computer.
"To master coding, one must understand not just what code looks like but what it does when executed," Meta researchers explain. This kind of reasoning is key for real program understanding, which goes far beyond copying code patterns.
Meta says CWM is meant to act like a "neural debugger," able to simulate program behavior before any code is actually run. The model can predict whether a program will finish or get stuck in an infinite loop. In tests using Meta's new HaltEval benchmark, CWM reached 94 percent accuracy.

CWM can also work backward from a description: given only a brief of what a program should do, it simulates execution and generates the corresponding code. The researchers demonstrate this with examples where CWM reconstructs functions from requirement descriptions and expected results, even when it has never seen the original code.
The model analyzes algorithm complexity too, estimating how long a program will run for different input sizes. On the BigOBench benchmark, CWM ranks second for predicting time complexity and outperforms other open-source models of similar size at 32 billion parameters.
CWM learned from over 120 million Python program executions, tracking how variables change step by step. The researchers call these "execution traces." During training, the model looked at both the code and the state of all local variables after every line, which helped it learn programming language semantics in a new way.
For realistic training, the team built more than 35,000 executable Docker containers from GitHub projects. Each container was a ready-to-use development environment so code and tests could run without extra setup.

Training happened in three phases: first, the model learned programming basics with 8 trillion tokens; then it trained on code execution with 5 trillion tokens; finally, it handled complex tasks through reinforcement learning across four environments, covering software engineering, competitive programming, and mathematical reasoning.
Benchmark results
CWM's performance shows up in benchmarks. On SWE-bench Verified, a main test of software engineering skills, the 32-billion-parameter model scored 65.8 percent on tasks with test-time scaling and 53.9 percent on the basic version. This is ahead of many smaller open-source models. But larger models, like Qwen3-Coder at up to 480 billion parameters, still lead the category.
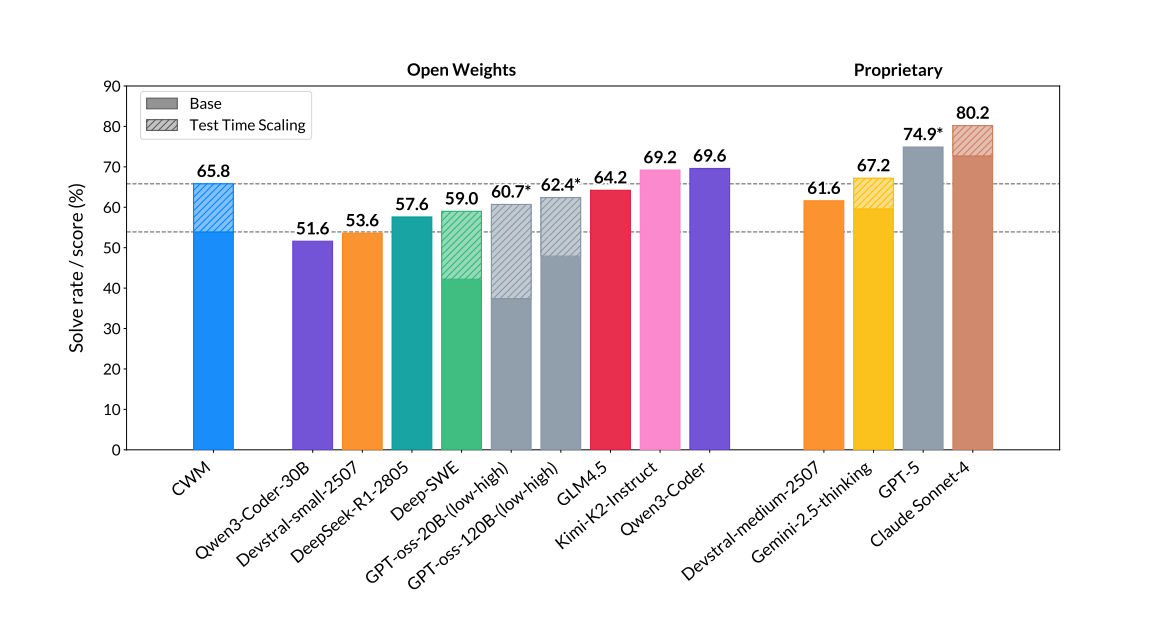
CWM also scores 68.6 percent on LiveCodeBench, 96.6 percent on Math-500, and 76 percent on the AIME 2024 Mathematical Olympiad. On CruxEval Output for code comprehension, it reaches 94.3 percent in reasoning mode.
Open for research
Meta has released CWM as an open-weights model under a non-commercial research license, sharing both the final model and intermediate training checkpoints through Hugging Face.
The 32-billion-parameter model can run on a single Nvidia H100 with 80 GB of memory, and it supports context windows up to 131,000 tokens.
Meta emphasizes that CWM is purely a research model focused on programming and mathematical reasoning. It hasn't been tuned for general chat or production use.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.