Meta's new translation system can translate 200 different languages. The universal machine translator is also expected to overcome hurdles in the Metaverse future.
Machine translation has gotten much better recently thanks to breakthroughs in natural language machine processing. Companies like DeepL are competing with human translators with high-quality machine translations.
Tech giants like Google and Meta are also developing their own AI systems for translation, mainly to make content more accessible on their platforms like YouTube, Facebook and Instagram.
But the systems trained for AI translation need data - and that's scarce for much of the world's spoken content. Researchers distinguish between so-called high-resource and low-resource languages - those for which there are already very many translations on the Internet, such as English, and those for which there are almost no translations.
Meta's "No Language Left behind" seeks the universal translator
Meta CEO Mark Zuckerberg, who wants to connect as many people as possible - currently still on Facebook and Instagram, in the future in the Metaverse - therefore sees the development of a "Universal Speech Translator" as an important task for his company.
In fact, Meta has been researching machine translation for years. In 2018, for example, it achieved great success with unsupervised trained AI systems and retranslation. In 2020, Meta introduced M2M-100, a system that can translate 100 languages. In 2021, an AI system based on it became the first multilingual AI model to achieve the highest score on the WMT2021 translation benchmark.
Such multilingual-trained AI models are considered the future of machine translation: unlike older systems, they are trained with dozens or hundreds of languages at a time and then transfer the knowledge they have gained from training with high-resource languages to low-resource languages.
Driven by the success of its multilingual models, Meta launched the "No Language Left behind" project in February 2022 to enable real-time universal translations, including for rare languages.
Zuckerberg called this multilingual capability a "superpower that people have always dreamed of." Such a translator could remove language barriers and give billions of people access to information in their preferred language, according to Meta's AI researchers.

Meta cracks the 200-language barrier
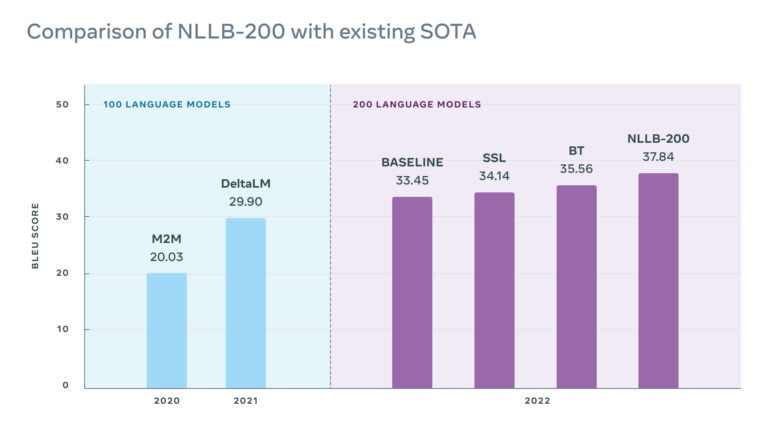
Now Meta is introducing NLLB-200, a multilingual AI model designed to translate 200 languages with high quality. To ensure translation quality, the team also created a 200-language evaluation dataset (FLORES-200) and tested NLLB-200 with it.
Compared to other multilingual models, NLLB-200 outperformed the current state of the art by an average of 44 percent. In some African and Indian languages, the Meta's system outperformed older systems by up to 70 percent.
Current translators support fewer than 25 African languages, many of which are of poor quality. Meta's new AI model, on the other hand, supports 55 African languages and is expected to deliver high-quality results.
This is made possible by advances in training resource collection, a larger AI model, and better evaluation and optimization of the model with FLORES-200. Thanks to a new version of the LASER toolkit for zero-shot transfer in computational linguistics based on a Transformer model, Meta was able to scale LASER3's language coverage, generate large sets of sentence pairs even for low-resource languages, and filter better thanks to the LID-200 model and a toxic language dataset.
Meta also works with human experts in both the collection of training data and the evaluation of translation quality, especially for low-resource languages.
The NLLB-200 model itself is based on a mixed-of-experts architecture, where specific areas of the neural network process specific languages. This prevents the system from becoming overwhelmed with so much language data, according to Meta. The artificial intelligence was also trained first with high-resource and then low-resource language pairs.
NLLB-200 has 54 billion parameters and was trained on Meta's new AI supercomputer, the Research SuperCluster (RSC).
Meta's NLLB-200 is open source
The techniques and insights developed for NLLB-200 are now being used to optimize and improve translations on Facebook and Instagram. According to Meta, there are already more than 25 billion translations per day combined on both platforms.
The availability of error-free translations in more languages could also make it easier to identify dangerous content and misinformation, protect the integrity of elections, and curb the spread of sexual abuse and human trafficking online, the company writes.
In addition, the AI translation will also be available to Wikipedia editors. Meta will also provide the fully trained NLLB-200 models, the FLORES-200 evaluation dataset, the training code for the model, and the code to replicate the training dataset under an open source license.