Meta's MusicGen can generate short new pieces of music based on text prompts, which can optionally be aligned to an existing melody.
Like most language models today, MusicGen is based on a Transformer model. Just as a language model predicts the next characters in a sentence, MusicGen predicts the next section in a piece of music.
The researchers decompose the audio data into smaller components using Meta's EnCodec audio tokenizer. As a single-stage model that processes tokens in parallel, MusicGen is fast and efficient.
The team used 20,000 hours of licensed music for training. In particular, they relied on an internal dataset of 10,000 high-quality music tracks, as well as music data from Shutterstock and Pond5.
MusicGen can handle both text and music prompts
In addition to the efficiency of the architecture and the speed of generation, MusicGen is unique in its ability to handle both text and music prompts. The text sets the basic style, which then matches the melody in the audio file.
For example, if you combine the text prompt "a light and cheerful EDM track with syncopated drums, airy pads and strong emotions, tempo: 130 BPM" with the melody of Bach's world-famous "Toccata and Fugue in D Minor (BWV 565)", the following piece of music can be generated.
Video: Meta
You can't precisely control the orientation to the melody, e.g., to hear a melody in different styles. It only serves as a rough guideline for the generation and is not exactly reflected in the output.
MusicGen just ahead of Google's MusicLM
The authors of the study ran tests on three versions of their model at different sizes: 300 million (300M), 1.5 billion (1.5B), and 3.3 billion (3.3B) parameters. They found that the larger models produced higher quality audio, but the 1.5 billion parameter model was rated best by humans. The 3.3 billion parameter model, on the other hand, is better at accurately matching text input and audio output.
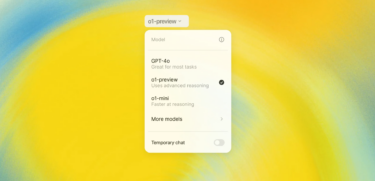
Compared to other music models such as Riffusion, Mousai, MusicLM, and Noise2Music, MusicGen performs better on both objective and subjective metrics that test how well the music matches the lyrics and how plausible the composition is. Overall, the models are just above the level of Google's MusicLM.
Meta has released the code and models as open source on Github, and commercial use is permitted. A demo is available on Huggingface.