
Systems like ChatGPT or Midjourney are mostly text or image experts. What happens when you combine these skills? Researchers at Microsoft are testing this with Kosmos-1, a model that combines image and text.
Multimodal AI models could develop a better understanding of the world by learning from different data sources, some researchers believe. They can combine knowledge from different modalities to solve tasks such as describing images in natural language.
"Being a basic part of intelligence, multimodal perception is a necessity to achieve artificial general intelligence, in terms of knowledge acquisition and grounding to the real world," writes the Microsoft research team. It presents Kosmos-1, a multimodal large language model (MLLM).
In addition to language and multimodal perception, a possible artificial general intelligence (AGI) would also need the ability to model the world and act, they say.
Kosmos-1 knows about language and images
Microsoft trained Kosmos-1 with partially related image and language data, such as word-image pairs. In addition, the team used large amounts of Internet text, as is common with large language models.
As a result, the model can understand images and text, including describing images in natural language, recognizing text on images, writing captions for images, and answering questions about images. Kosmos-1 can perform these tasks on direct request or, similar to ChatGPT, in a dialog situation.

Because it has the same text capabilities as large language models, it can also use methods such as chain-of-thought prompting to produce better results.

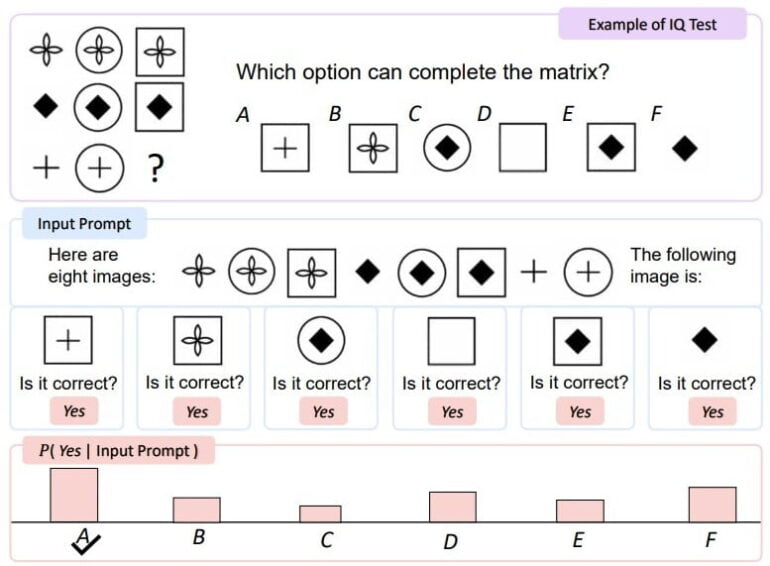
On a visual IQ test, KOSMOS-1 performed about five to nine percent better than chance, which the research team believes shows that KOSMOS-1 can perceive abstract conceptual patterns in a nonverbal context by combining nonverbal reasoning with the perception of linguistic patterns. However, there is still a large performance gap with the average adult level.
The ability of multimodal models to represent implicit connections between different concepts has already been demonstrated in the OpenAI study of CLIP neurons.

Multimodal AI as a possible next step in AI development
Microsoft's approach is not new; the German company Aleph Alpha presented MAGMA, a combined image language model, and M-Vader, a method for multimodal prompting. Google presented the "Future of Google Search" in the spring of 2021 with MUM, which enables multimodal queries and provides more contextual knowledge.
Deepmind's Flamingo, which also combines language and image processing, goes in a similar direction. The Microsoft research team also used Flamingo to benchmark Kosmos-1's performance in tests such as image captioning and answering questions about image content. The Microsoft model performed as well as, and in some cases slightly better than, Kosmos-1.
The researchers also trained a language model (LLM) on the same text data as Kosmos-1 and had the two models compete in language-only tasks.
Here the two models tied in most cases, with Kosmos-1 performing significantly better on visual reasoning tasks that require an understanding of the properties of everyday real-world objects such as color, size, and shape, the team says.
The reason for KOSMOS-1’s superior performance is that it has modality transferability, which enables the model to transfer visual knowledge to language tasks. On the contrary, LLM has to rely on textual knowledge and clues to answer visual commonsense questions, which limits its ability to reason about object properties.
From the paper
Multimodal large language models combine the best of both worlds, the researchers write: In-context learning and the ability to follow natural language instructions from large language models, and "perception is aligned with language models by training on multimodal corpora."
The results of Kosmos-1 are "promising" across a wide range of language and multimodal tasks, they say. Multimodal models would offer new capabilities and opportunities compared to large language models.
Kosmos-1 has 1.6 billion parameters, which is tiny compared to today's large language models. The team would like to scale up Kosmos-1 to include more modalities, such as speech, in model training. A larger model with more modalities could then overcome many of the current limitations, the researchers write.




