Mixtral 8x7B is currently the best open-source LLM, surpassing GPT-3.5

Update –
- Added Mixtral 8x7B paper
Update from January 9, 2024:
Mistral AI has published the Mixtral 8x7B paper, which describes the architecture of the model in detail. It also contains extensive benchmarks comparing it to LLaMA 2 70B and GPT-3.5.
In the much-cited language comprehension benchmark MMLU, Mixtral is ahead of the two models mentioned above. Larger models such as Gemini Ultra or GPT-4 achieve between 85 and 90 percent, depending on the prompt method.
On the LMSys Leaderboard, where humans rate the AI's answers, Mixtral 8x7b is just ahead of Claude 2.1 and GPT-3.5, as well as Google's Gemini Pro. GPT-4 is clearly in the lead.
This confirms the pattern of the past few months: it seems relatively easy for many organizations to achieve a model at or slightly above the level of GPT-3.5. But GPT-4 remains unmatched.
Original article from December 11, 2023:
Mixtral 8x7B is currently the best open source LLM, says Mistral
Mistral AI has released its new Mixtral 8x7B language model, detailing its performance in a new blog post. It is claimed to be the best open language model currently available.
At the end of last week, Mistral released a new language model via a torrent link. Today, the company has released more details about the Mixtral 8x7B model, as well as announcing an API service and new funding.
According to the company, Mixtral is a sparse Mixture-of-Experts (SMoE) model with open weights, licensed under Apache 2.0. A similar architecture is rumored to be used by OpenAI for GPT-4. Mixtral selects two of the eight parameter sets for a query and uses only a fraction of the total number of parameters per inference, reducing cost and latency. Specifically, Mixtral has 45 billion parameters but uses only 12 billion parameters per token for inference. It is the largest model to date from the start-up, which released the relatively powerful Mistral 7B in September.
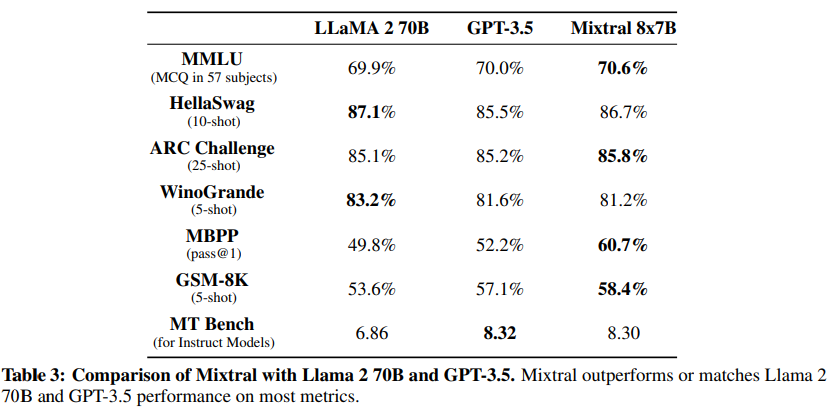
Mixtral 8x7B outperforms Meta's LLaMA 2 70B
According to Mistral, Mixtral outperforms Llama 2 70B in most benchmarks and offers 6 times faster inference. It is also said to be more truthful and less biased than the Meta model. According to Mistral, this makes it the "strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs." In standard benchmarks, it also matches or outperforms OpenAIs GPT-3.5.
Mixtral handles up to 32,000 token contexts, supports English, French, Italian, German, and Spanish, and can write code.
Mistral releases Instruct version of Mixtral
In addition to the base Mixtral 8x7B model, Mistral is also launching Mixtral 8x7B Instruct. The model has been optimized for precise instruction through supervised fine-tuning and Direct Preference Optimisation (DPO). It achieves a score of 8.30 in MT-Bench, making it the best open-source model with performance comparable to GPT-3.5.
Mixtral is available in beta on the Mistral platform. The smaller Mistral 7B and a more powerful prototype model that outperforms GPT-3.5 are also available there, Mistral said.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.