ModernBERT is a "workhorse model" that brings faster, cheaper text processing for tasks like RAG

Answer.AI and LightOn announced ModernBERT, a new open-source language model that improves upon Google's BERT in speed, efficiency, and quality.
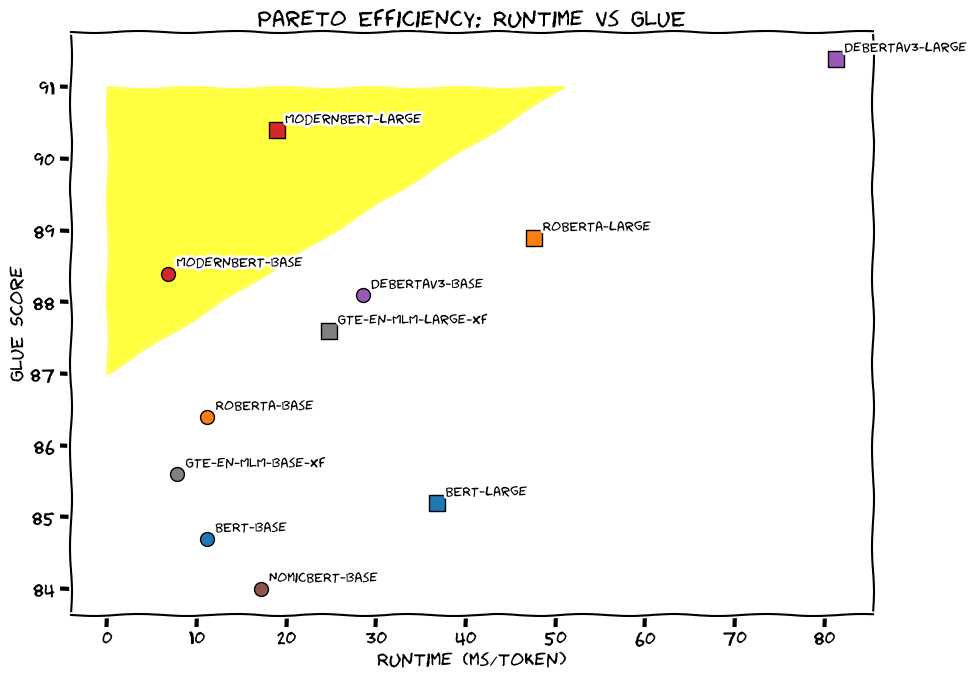
The encoder-only model processes text up to four times faster than its predecessor while using less memory, according to a blog post from the developers. The team trained ModernBERT on 2 trillion tokens from web documents, programming code, and scientific articles.
ModernBERT can handle texts up to 8,192 tokens long—16 times more than the typical 512-token limit of existing encoder models. It's also the first encoder model trained extensively on programming code. The model scored above 80 on the StackOverflow Q&A dataset, setting a record for encoder-only models.
The developers liken ModernBERT to a Honda Civic tuned for the racetrack: "When you get on the highway, you generally don’t go and trade in your car for a race car, but rather hope that your everyday reliable ride can comfortably hit the speed limit."
Major cost reductions for large-scale text processing
While large language models such as GPT-4 charge several cents per query and take seconds to respond, ModernBERT runs locally and is much faster and cheaper, according to the developers.
For example, filtering 15 trillion tokens in the FineWeb Edu project cost $60,000 using a BERT-based model. The same task would have cost over $1 million even with Google Gemini Flash, the cheapest decoder-based option.
The developers say ModernBERT is well-suited for many real-world applications, from retrieval-augmented generation (RAG) systems to code search and content moderation. Unlike GPT-4, which needs specialized hardware, the model runs effectively on consumer-grade gaming GPUs.
ModernBERT is available in two versions: a base model with 139 million parameters and a large version with 395 million parameters. Both models are now on Hugging Face with an Apache 2.0 license, and users can drop them in as direct replacements for their current BERT models. The team plans to release a larger version next year but has no plans for multimodal capabilities.
To promote development of new applications, the developers launched a competition that will award $100 and a six-month Hugging Face Pro subscription to each of the five best demos.
Google introduced BERT (Bidirectional Encoder Representations from Transformers) in 2018, using it primarily for Google Search. The model remains one of the most popular on HuggingFace, with more than 68 million monthly downloads.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.