Most AI models fail at self-criticism, but OpenAI's o1-mini keeps getting better for a while

Researchers at the Chinese University of Hong Kong, Shenzhen, along with teams from Alibaba's Qwen and the Shenzhen Research Institute of Big Data, have found something interesting about OpenAI's o1-mini model. While most AI systems get worse when trying to fix their own mistakes, o1-mini usually improves its performance.
The difference really shows up in math problems. When working on college-level math, o1-mini got 24 percent better through self-criticism, and improved by 19.4 percent on ARC tasks. The researchers tested it against some other LLMs like GPT-4o, Qwen2.5 models, Mistral Large, and Llama 3.1, though they didn't include the larger o1 model, o1-Pro, or any Claude models.
RealCritic: constructive self-criticism desired
The team created a new testing method called RealCritic that goes beyond just checking if an AI can spot its mistakes - it makes sure the AI can actually fix them too. The process works like a feedback loop: the AI gets a task and solution, reviews it critically, and then has to come up with something better. The criticism only counts if the new answer actually improves on the original.
This is different from older tests that just checked if AI could point out errors without proving it could fix them. As the researchers put it, "recognizing that a critique is high-quality if it contributes meaningfully to the self-improvement of LLMs, we propose to measure critique quality directly based on the correction it enables."
Classic models fail with self-criticism
The study looked at three different ways AI models can critique solutions. In self-critique, where models review their own work, most actually did worse. O1-mini was the exception, improving by that 3.3 percent average.
Things went better when models critiqued each other's work. All models showed improvement here, with o1-mini leading the pack with a 15.6 percent boost in performance.
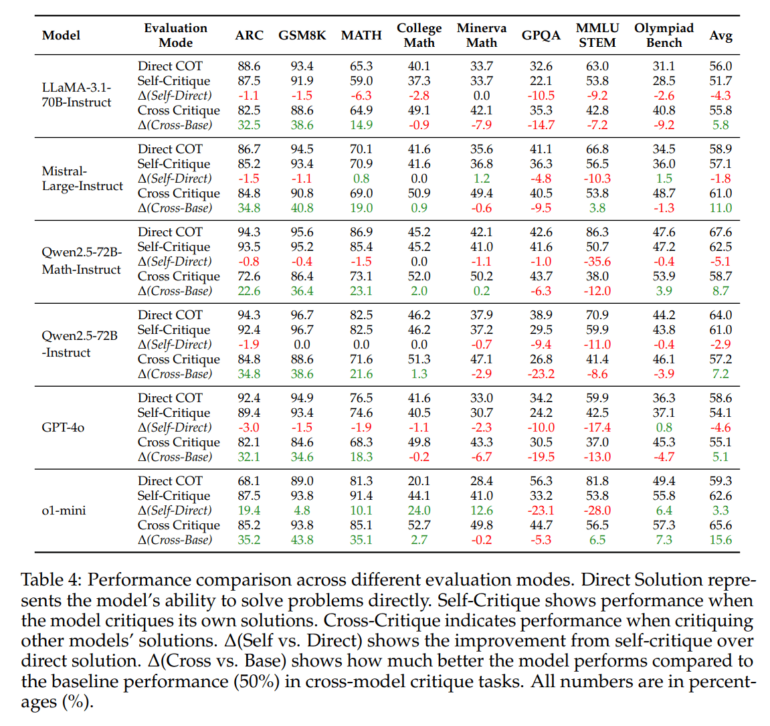
The researchers also tested how well models could improve over multiple rounds of iterative feedback. Most models like LLaMA and Mistral either plateaued or got worse after the first round. O1-mini kept improving for three rounds before hitting its limit at about 67 percent accuracy.
Qwen2.5-72B-Instruct also showed impressive consistency - it was the only traditional model that maintained steady improvement across multiple rounds, though it never reached o1-mini's performance levels.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.