Multimodal prompting is key for better generative AI

European AI company Aleph Alpha introduces an innovation for generative image models: multimodal prompts. Thanks to the new technique, AI models can be guided more precisely.
Generative AI models like OpenAIs DALL-E 2, Midjourney, or Stable Diffusion process text to generate original images. In contrast, the M-VADER diffusion model developed by Aleph Alpha together with TU Darmstadt can fuse multimodal inputs such as a photo or a sketch, and a textual description into a new image idea.
At the heart of the M-Vader architecture is the S-MAGMA multimodal decoder with 13 billion parameters. It combines the MAGMA image-language model with a Luminous 13B model fine-tuned for semantic search. Both pre-trained models originate from Aleph Alpha. The output of S-MAGMA guides the image generation process with a Stable Diffusion version fine-tuned for multimodal input.
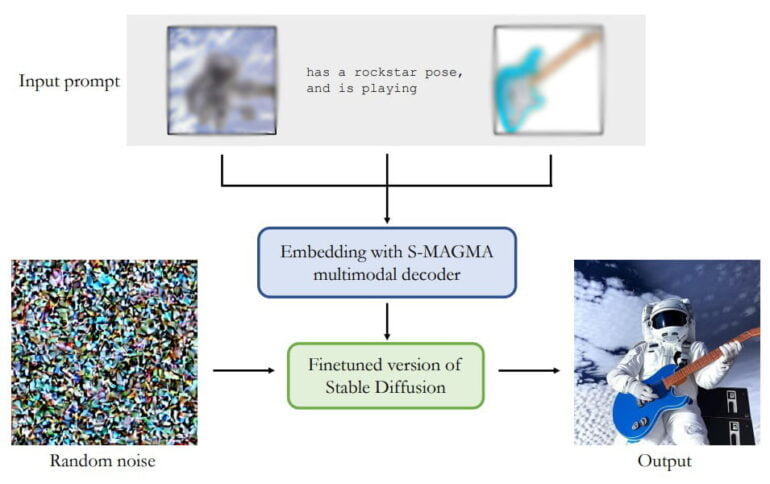
According to the team, M-Vader can generate images based on multimodal context, create a new image from two images, or create variations of an image. The following graphic shows some examples of merging multiple images together with text instructions to create a new image.
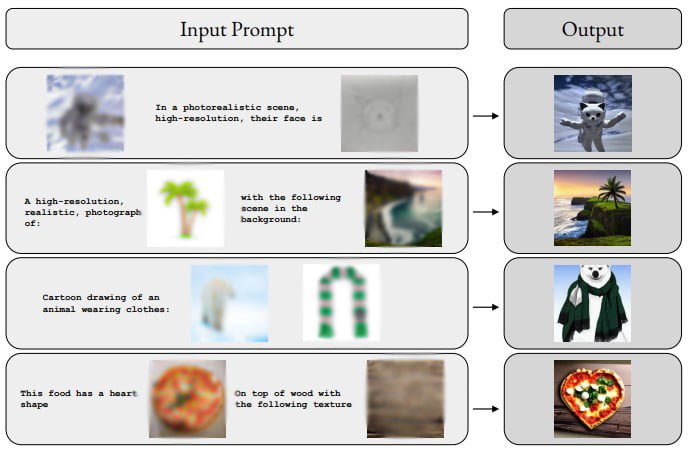
Until now, AI imaging models mainly process text to generate original images. In contrast, the M-VADER diffusion model developed by Aleph Alpha together with TU Darmstadt can fuse multimodal inputs such as a photo, a sketch, and a textual description into a new image idea.
From the paper
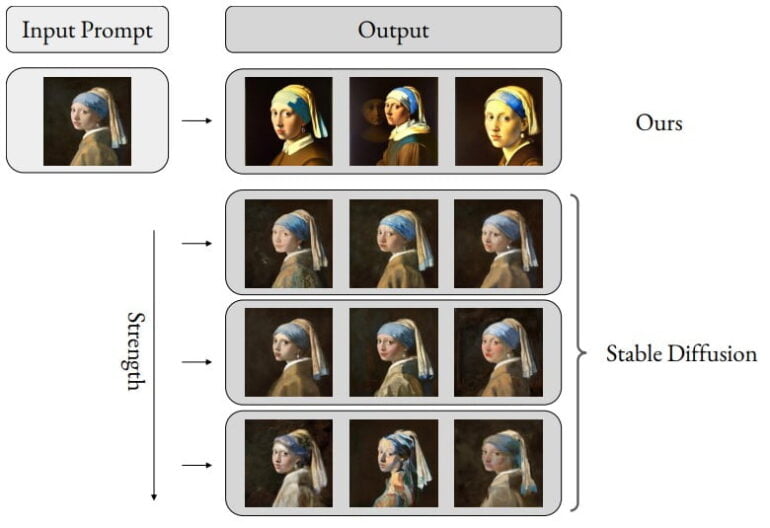
Multimodal prompts become part of Aleph Alpha's Luminous models
The researchers see their work on multimodal prompts as a contribution to the development of AI models that can better capture user intentions. There are more image examples in the paper.
With Luminous and Magma, Aleph Alpha already offers two AI base models in different scales for text and image captioning generation. According to Jonas Andrulis, CEO of Aleph Alpha, the multimodal image generation technology now unveiled is a world first. It is soon to become part of the Luminous offering.
"Our knowledge is not just text but multimodal and AI needs to be able to understand language and images together," Andrulis writes.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.