New Energy-Based Transformer architecture aims to bring better "System 2 thinking" to AI models
A new architecture called the Energy-Based Transformer aims to teach AI models how to solve problems analytically and step by step.
Most current AI models operate much like what Daniel Kahneman described as "System 1 thinking": they're fast, intuitive, and excel at pattern recognition. But according to a study from researchers at UVA, UIUC, Stanford, Harvard, and Amazon GenAI, these models often fail at tasks that require the slower, more analytical "System 2 thinking" - such as complex logical reasoning or advanced mathematics.
The paper, "Energy-Based Transformers are Scalable Learners and Thinkers," asks whether these kinds of reasoning skills can emerge purely from unsupervised learning. The researchers' answer is a new architecture: the Energy-Based Transformer (EBT).
How Energy-Based Transformers work
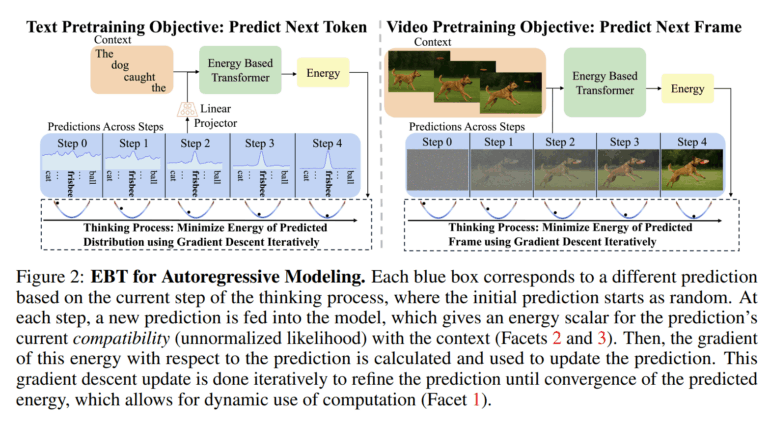
The EBT approach treats thinking as an iterative optimization process. Instead of generating an answer in a single step, the model starts with a random solution. It then evaluates this solution by calculating an "energy" value.
The lower the energy, the better the prediction fits the context. Through repeated adjustments using gradient descent, the answer is gradually refined until the energy reaches a minimum. This lets the model spend more computation on harder problems.
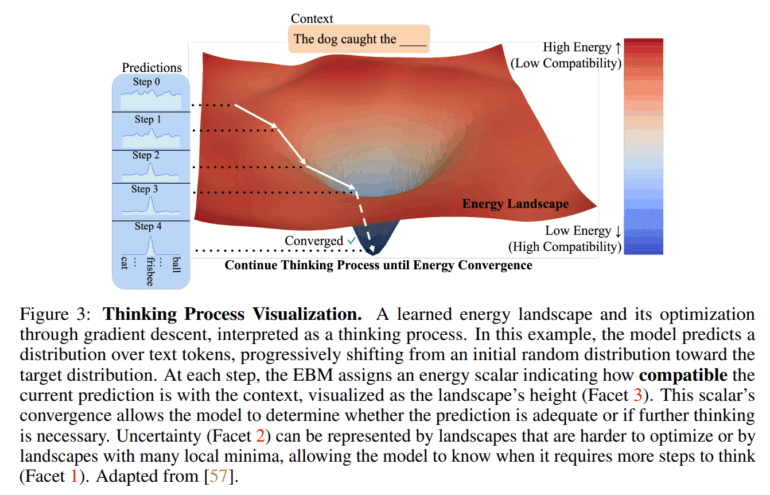
The idea of framing this process in terms of energy isn't new - Meta's chief AI scientist Yann LeCun and others have discussed "energy-based models" for years.
More efficient learning and generalization
In experiments, the researchers compared EBTs with an advanced Transformer variant (Transformer++). Their results suggest EBTs scale more efficiently: the paper reports up to a 35 percent higher scaling rate in terms of data, parameter count, and compute. This points to improved data and computational efficiency.
The real strength, however, shows up in what the authors call "thinking scalability" - the ability to boost performance by allocating extra compute at runtime. On language tasks, EBTs improved performance by up to 29 percent, especially on problems that differed significantly from their training data.
In image denoising tests, EBTs outperformed Diffusion Transformers (DiTs) while requiring 99 percent fewer computation steps. The study also found that EBTs learned image representations that delivered roughly ten times better classification accuracy on ImageNet-1k, suggesting a deeper understanding of content.
Significant hurdles remain
Despite these promising results, open questions remain. The main issue is compute: according to the paper, training EBTs requires 3.3 to 6.6 times more computing power (FLOPs) than standard Transformers. This extra overhead could be a barrier for many real-world applications. The study also measures "System 2 thinking" mainly through perplexity improvements, rather than actual reasoning tasks, and comparisons to state-of-the-art reasoning models are missing due to limited compute budgets.
All scaling predictions are based on experiments with models up to just 800 million parameters - much smaller than today's largest AI systems. Whether EBTs' advantages hold at larger scales remains to be seen.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.