New RAG system RetroLLM is more efficient and accurate than previous solutions

Researchers have developed a more streamlined approach to help AI systems process information. The new system, called RetroLLM, combines two previously separate steps - searching for information and writing text - into a single process.
A team from Renmin University of China, Tsinghua University, and Huawei's Poisson Lab developed RetroLLM to make AI systems more efficient. Traditional RAG systems (retrieval-augmented generation) had to work in two separate phases: first finding relevant information, then creating text from it. RetroLLM handles both tasks simultaneously, using less computing power while delivering more accurate results.
How RetroLLM works
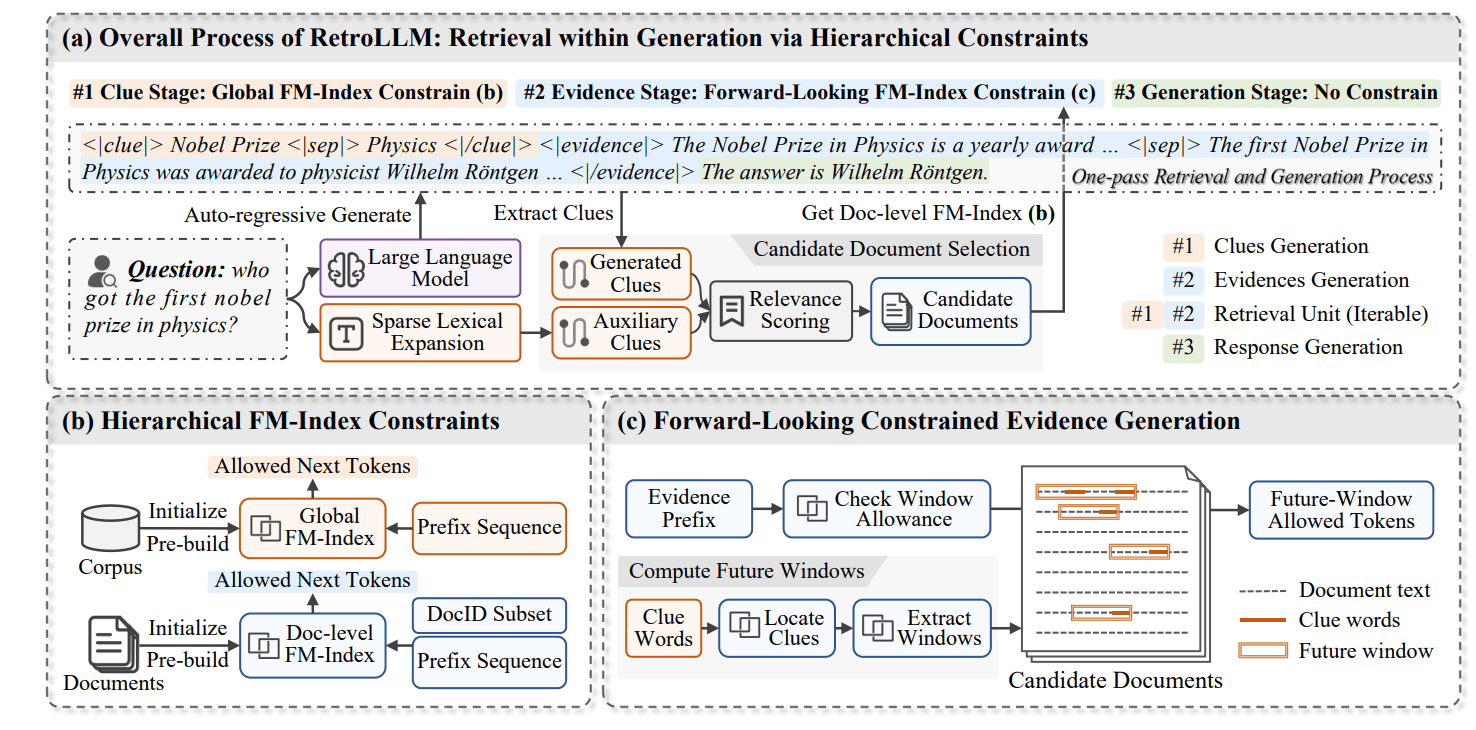
The system operates in three main steps. First, it creates "clues" - key words or phrases based on the original question. For example, if someone asks about the first physics Nobel Prize winner, the system identifies terms like "Nobel Prize" and "physics."
Next, RetroLLM processes information using several advanced techniques. It evaluates multiple potential text paths at once (constrained beam search), like exploring different branches of a decision tree while focusing on the most promising ones. The system can also predict which sections will be useful before fully processing them (Forward-Looking Constrained Decoding), helping it avoid time spent on irrelevant content.
To handle large amounts of text efficiently, RetroLLM uses a sophisticated indexing system (hierarchical FM index constraints) that works like a detailed roadmap, helping it quickly locate exactly the information it needs at different levels of detail.
Better results, one trade-off
In testing, RetroLLM showed impressive results, achieving 10-15 percent higher accuracy than existing systems. It particularly excels at handling complex questions that require combining information from multiple sources.
The system adapts its approach based on each question. For simple queries, it might only need a few key facts. For more complex questions, it automatically searches deeper and pulls from additional sources.
While RetroLLM uses less computing power overall, researchers found one limitation: it's slightly slower than simpler systems when processing individual queries. The team believes using a combination of smaller and larger models could help solve this issue in the future.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.