Nvidia can precisely control computer characters using only language

To control the behavior of physics-based characters through language, Nvidia's PADL combines a language model with reinforcement learning.
One thing that comes to mind when remembering the start of this wave of AI is certainly the strangely moving 3D figures from Deepmind and other research institutions. These three-legged spiders or humanoid 3D puppets had learned their movements through reinforcement learning.

There are now numerous approaches to making digital animals or human-like figures learn movements on their own. The goal of these methods is to develop AI systems that can generate natural-looking movements for a variety of simulated figures and thus complement or replace manual animation and motion capture processes in the long term.
Nvidia's PADL makes AI animation controllable by language
For AI animation to be used in industrial workflows, it must be controllable. Nvidia now introduces "Physics-based Animation Directed with Language" (PADL), a framework that combines advances in natural language processing with reinforcement learning methods to create a language-driven system.
PADL is trained in three stages: In the skill embedding phase, Nvidia uses a language encoder and a motion encoder to train a shared embedding space with short videos with motions and associated text descriptions.
The embedding space combines language and skills seen in the video and is used in the second phase to learn multiple policies for solving simple tasks, such as moving toward a specific object. In the third phase, Nvidia merges the different learned policies (multitask aggregation).
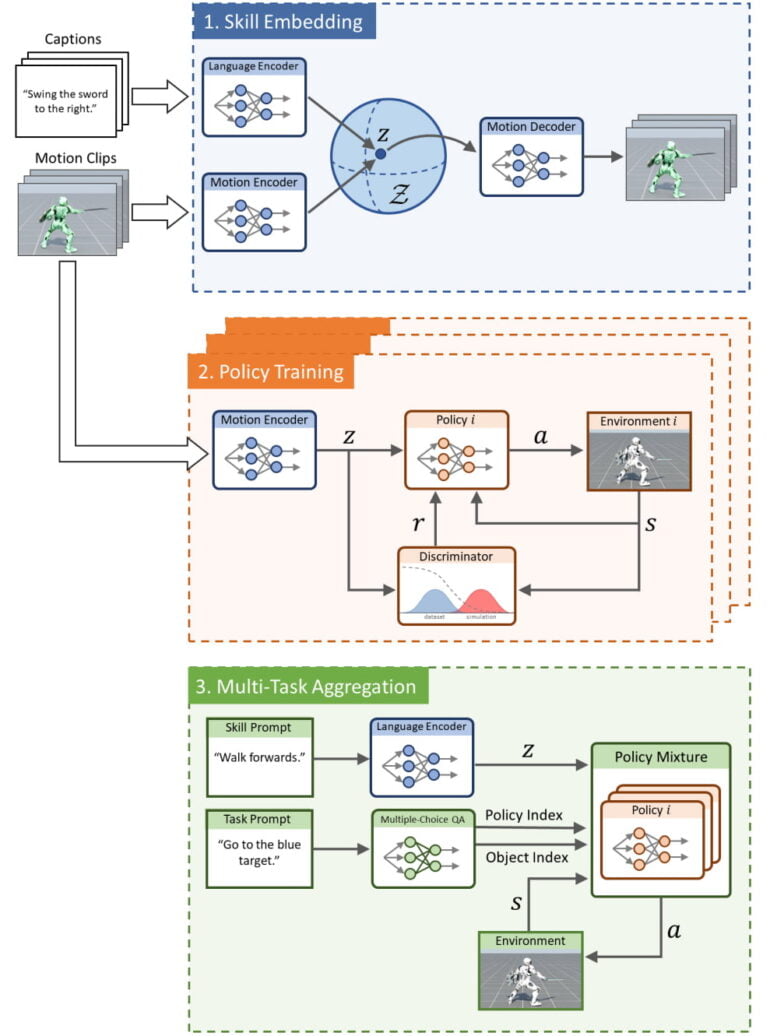
The resulting model can then be controlled by language: Users can use text input to assign a character a specific task and a corresponding skill, such as "sprint to the red block" or "face the target and hit it with the shield."
Characters automatically learn related movements
By training with different movements and corresponding text descriptions, the model can interpolate between related movements, such as slow walking and sprinting.
In the video, you can see the character gradually increasing its speed or slowly squatting from a standing position without having seen the intermediate steps in training. However, the model is overwhelmed with completely new skills, such as cartwheels and unseen tasks.
Nvidia wants to train PADL with a much larger dataset of annotated motion capture recordings for more skills, and abandon the few fixed tasks in favor of a more general approach to policy training.
More information can be found on the PADL project page. The code will be released there soon.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.