Nvidia researchers urge the AI industry to rethink agentic AI in favor of smaller, more efficient LLMs

Nvidia researchers say the AI industry is too focused on oversized large language models (LLMs) for agent systems, a strategy they argue is both economically and environmentally unsustainable.
In a recent paper, they suggest most agents could run just as well on smaller language models (SLMs) and urge companies to rethink their approach.
The market for LLM APIs that power agent systems was valued at $5.6 billion in 2024, but cloud infrastructure spending for these systems hit $57 billion, a 10-to-1 gap. "This operational model is deeply ingrained in the industry — so deeply ingrained, in fact, that it forms the foundation of substantial capital bets," they write.
SLMs, which they define as models under 10 billion parameters, are, in their view, "principally sufficiently powerful," "inherently more operationally suitable," and "necessarily more economical" for most agent workloads.
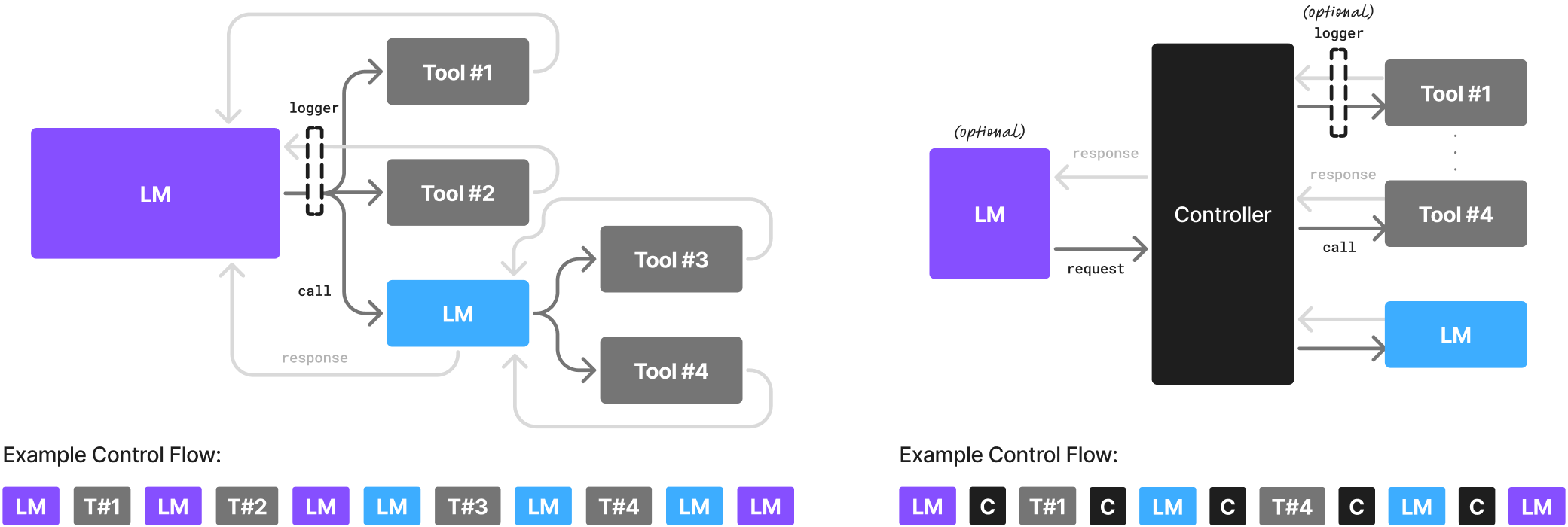
The researchers argue that smaller models can often match or beat much larger ones. They cite Phi-2 from Microsoft, which they say rivals 30-billion-parameter LLMs in reasoning and code while running 15 times faster. Nvidia’s Nemotron-H models, with up to 9 billion parameters, reportedly deliver similar accuracy to 30-billion-parameter LLMs using far less compute. They also claim Deepseek-R1-Distill-Qwen-7B and DeepMind’s RETRO match or outperform much larger proprietary models on key tasks.
The economics lean small
Nvidia's researchers say the math favors SLMs. Running a 7‑billion‑parameter model costs 10 to 30 times less than operating a 70‑ to 175‑billion‑parameter LLM, factoring in latency, energy use, and compute requirements. Fine‑tuning can be done in a few GPU hours instead of taking weeks, making small models much faster to adapt. Many can also run locally on consumer hardware, which cuts latency and gives users more control over their data.
The team also claims SLMs use their parameters more efficiently, while large models often activate only a small fraction for a given input—an inefficiency they see as built‑in. They argue that AI agents rarely need the full range of capabilities an LLM provides. "An AI agent is essentially a heavily instructed and externally choreographed gateway to a language model," they write.
Most agent tasks are repetitive, narrowly scoped, and not conversational, which makes specialized SLMs fine‑tuned for those formats a better fit. Their recommendation is to build heterogeneous agent systems that rely on SLMs by default, reserving larger models for situations that truly require complex reasoning.
Why SLMs aren't taking over
According to Nvidia's team, the biggest barriers are the industry's heavy investment in centralized LLM infrastructure, its focus on broad benchmark scores, and the lack of public awareness about how capable small models have become.
They lay out a six‑step plan for making the shift: collect data, filter and curate it, cluster tasks, pick the right SLM, fine‑tune it for specific needs, and keep improving over time. In case studies, they found that 40 to 70 percent of LLM queries in open‑source agents like MetaGPT, Open Operator, and Cradle could be handled just as well by SLMs.
The researchers observe that for many, the shift to SLMs represents "not only a technical refinement but also a Humean moral ought" in light of rising costs and the environmental toll of large‑scale infrastructure. Mistral recently supported that view when it released detailed data on the energy consumption of its largest models.
It might seem odd for Nvidia, one of the biggest beneficiaries of the LLM boom, to make this argument. But pushing smaller, cheaper models could grow the overall AI market and help embed the technology more deeply across businesses and consumer devices. Nvidia is seeking feedback from the community and plans to publish selected responses online.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.