Nvidia's Magic3D can create 3D objects based on text input. The model is supposed to significantly outperform Google's Dreamfusion text-to-3D model, which was only introduced in September.
Like Dreamfusion, Magic3D relies at its core on an image generation model that uses text to create images from different perspectives, which in turn serve as input for 3D generation. Nvidia's research team uses its in-house image model eDiffi for this, while Google relies on Imagen.
The advantage of this method is that the generative AI model does not have to be trained with scarce 3D models. Unlike Nvidia's freely available text-to-3D model Get3D, Magic3D can also generate many 3D models from different categories without additional training.
From coarse to fine
With Magic3D, Nvidia goes from coarse to fine: First, eDiffi generates low-resolution images based on text, which are then processed into an initial 3D representation via Nvidia's Instant NGP framework.
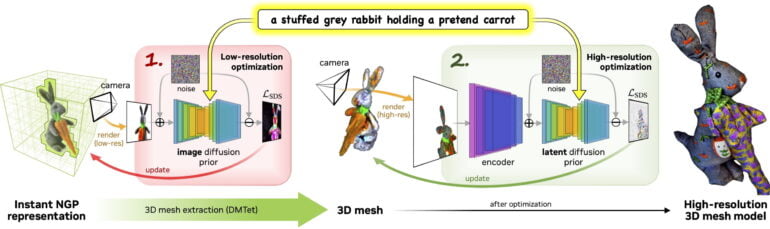
Using the DMTet AI model optimized for this purpose, the team then extracts a higher-quality 3D mesh from the simple NGP representation. This serves as a template for further 2D images, which are upscaled and then used to optimize the 3D mesh.
The result is a 3D model with a resolution of up to 512 x 512 pixels that can be imported and visualized in standard graphics software, according to Nvidia.
Augmenting 3D content creation with natural language could considerably help democratize 3D content creation for novices and turbocharge expert artists.
From the paper
Magic3D outperforms Dreamfusion in resolution and speed
According to the Nvidia research team, Magic3D takes half the time to create a 3D model compared to Dreamfusion - about 40 minutes instead of an average of one and a half hours - at eight times the resolution.
The following video explains the creation process and shows 3D model comparisons with Dreamfusion starting at minute 2:40. In initial tests, 61 percent of users preferred Magic3D models over Dreamfusion 3D models.
Video: Nvidia
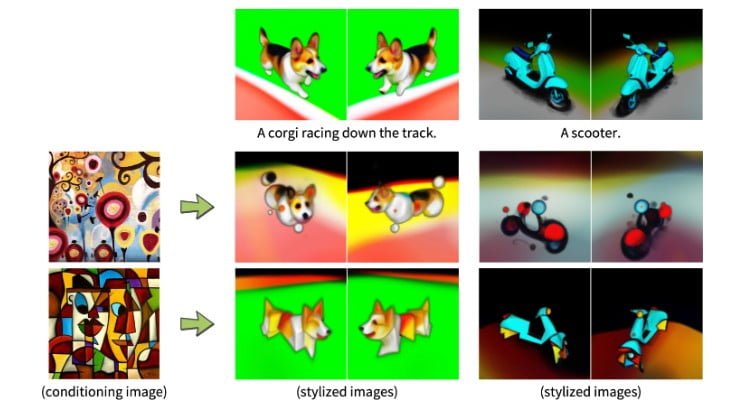
Magic3D also offers editing functions typical for image AI systems, which can be transferred to the 3D generation process. For example, text prompts can be adjusted after the initial generation: A squirrel on a bicycle turns into a rabbit on a scooter.

Dreambooth fine-tuning of the eDiffi diffusion model also allows optimization of generated 3D models to specific subjects. The model can also transfer the style of an input image to a 3D model.
Nvidia's research team hopes Magic3D can "democratize 3D synthesis" and encourage creativity in 3D content creation. This seems to be in the spirit of Silicon Valley venture capital firm Andreessen Horowitz: It speculates that generative AI will transform the gaming sector, which relies on all kinds of media formats and 3D content in particular.