OpenAI claims a breakthrough in LLM reasoning on complex math problems
Update –
- Added statements from OpenAI researcher Jerry Tworek
Update as of July 20, 2025:
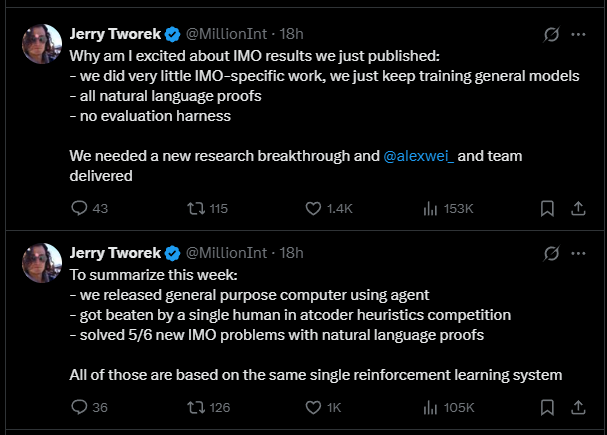
OpenAI researcher Jerry Tworek confirmed on X that the model below received "very little IMO-specific work"—just continued training of the general-purpose base models. All solutions relied on natural language proofs without any special evaluation framework.
Tworek called the achievement a genuine research breakthrough delivered by Alexander Wei's team. He later added that a public release of the model is possible by the end of the year.
Tworek also noted that all of OpenAI’s major announcements this week—the general AI agent system, a close loss to a human in a heuristic programming contest, and solving 5 of 6 IMO problems—came from the same reinforcement learning system. According to Twore, ChatGPT agent runs on an earlier version built on an older base model.
There are rumors that DeepMind has also earned a gold medal in the IMO contest, though the company has not made any official announcement. Last year, DeepMind's AlphaProof and AlphaGeometry systems took silver by solving four out of six problems.
While OpenAI claims to use a standard language model, it remains unclear what approach either team used this year. In 2024, DeepMind's silver-medal systems relied on a hybrid method that combined a pre-trained LLM with elements from classic search algorithms.
Article from July 19, 2025:
OpenAI says its experimental language model has solved International Mathematical Olympiad (IMO) problems at a gold medal level—a possible breakthrough for AI with general reasoning skills. The results have not yet been independently confirmed.
According to OpenAI researchers Alexander Wei and Noam Brown, the model tackled the IMO 2025 competition, solving the first five of the six official problems and earning 35 out of a possible 42 points.
The IMO is considered the most difficult math competition for high school students, requiring creativity and rigorous logical reasoning. Wei claims this is the first AI model that can "craft intricate, watertight arguments at the level of human mathematicians."

The model generated its solutions under standard competition conditions: two 4.5-hour sessions, no outside help, all answers written in natural language, and no tool use. Former IMO medalists graded the responses anonymously. The full solutions are available on GitHub.
Still room to scale
Unlike DeepMind's AlphaGeometry, which is built specifically for math, OpenAI's model is a general-purpose reasoning language model. "We reach this capability level not via narrow, task-specific methodology, but by breaking new ground in general-purpose reinforcement learning and test-time compute scaling," Wei explains.
Brown confirms that the model relies on "new experimental general-purpose techniques" and scales its compute at test time, though he doesn't share the technical details.
"o1 thought for seconds. Deep Research for minutes. This one thinks for hours," Brown notes, pointing out that the new model is more efficient and still has scaling potential. He argues that even a small advantage over human performance can be enough to drive major scientific progress.
Wei says OpenAI has no plans to release this model or a similar one in the coming months, stressing that it's strictly a research project. He also clarified that while GPT-5 is planned "soon", it is unrelated to the IMO model, which was developed by a small team led by Wei.
Brown points out that the technology could eventually become a product, and with progress moving so quickly, future versions may be even more advanced. He adds that the results surprised even people inside OpenAI, calling it "a milestone that many considered years away."
Current models are far behind
The timing of OpenAI's announcement seems intentional, coming just after current AI models delivered disappointing results at the same competition.
A recent evaluation by the MathArena.ai platform tested several leading models-including Gemini 2.5 Pro, Grok-4, DeepSeek-R1, and even OpenAI's own o3 and o4-mini-on the IMO 2025 tasks. None of them managed to score the 19 points needed for a bronze medal. Gemini 2.5 Pro came out on top, but with only 13 out of 42 points, while the others performed even worse.

Even with extensive testing, which included a best-of-32 selection process and evaluations by IMO experts, the models showed serious flaws. The results were filled with logical errors, incomplete arguments, and even made-up theorems.
Viewed in this context, OpenAI's announcement looks like a direct response to the limitations exposed by the MathArena test. While the achievement is significant, its true value will depend on whether the results can be independently reproduced and applied to real scientific problems.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.