
OpenAI publishes a paper on the new image AI DALL-E 3, explaining why the new image AI follows prompts much more accurately than comparable systems.
As part of the full rollout of DALL-E 3, OpenAI publishes a paper about DALL-E 3: It addresses the question of why DALL-E 3 can follow prompts so accurately compared to existing systems. The answer is in the title of the paper already: "Improving Image Generation with Better Captions"
Prior to the actual training of DALL-E 3, OpenAI trained its own AI image labeler, which was then used to relabel the image dataset for training the actual DALL-E 3 image system. During the relabeling process, OpenAI paid particular attention to detailed descriptions.
Before training DALL-E 3, OpenAI trained three image models experimentally with three annotation types: human, short synthetic, and detailed synthetic.

Even the short synthetic annotations significantly outperformed human annotations in benchmarks. The long descriptive annotations performed even better.
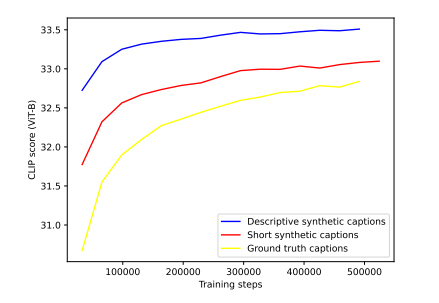
OpenAI also experimented with a mix of different synthetic and human annotation styles. However, the higher the percentage of machine annotation, the better the image generation. For example, DALL-E 3 contains 95 percent machine annotations and 5 percent human annotations.
Prompt following: DALL-E 3 is ahead of Midjourney 5.2 and Stable Diffusion XL
OpenAI tested the prompt following accuracy of DALL-E 3 in synthetic benchmarks and with human testers. In all synthetic benchmarks, DALL-E 3 outperforms its predecessor, DALL-E 2, and Stable Diffusion XL, in most cases by a significant margin.
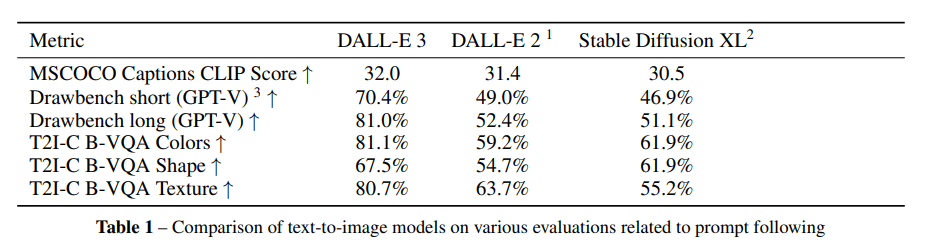
More relevant is the human evaluation in the dimensions Prompt following, Style and Coherence. In particular, the result for Prompt following is clearly in favor of DALL-E 3 compared to Midjourney.

But OpenAI's new image AI also performs significantly better than Midjourney 5.2 in terms of style and coherence, with the open-source image AI Stable Diffusion XL falling even further behind. According to OpenAI, DALL-E 3 still has problems locating objects in space (left, right, behind, etc.).
In a footnote, OpenAI points out that the image labeling innovation is only part of what's new in DALL-E 3, which has "many improvements" over DALL-E 2. Thus, the clear advantage of DALL-E 3 over competing systems is not solely due to synthetic image labeling. OpenAI does not address the other improvements of DALL-E 3 in the paper.
Don't count out Midjourney just yet
As a heavy Midjourney user, I am impressed with DALL-E 3's ability to follow my prompts fairly accurately. For THE DECODER, we use a lot of AI-generated illustrations. The more accurate they are to the subject of the article, the better. That's why I've largely switched to DALL-E 3 at this point.
In terms of image quality, however, I still see Midjourney ahead. DALL-E 3 sometimes tends to have a generic stock-photo look. Especially in photorealistic scenes, DALL-E 3 is worse. People often look synthetic. In addition, Midjourney gives me much more creative leeway in terms of content and technique when it comes to prompting.
Midjourney also wants to improve the accuracy of the prompting in v6 and could catch up with DALL-E 3. DALL-E 2 by OpenAI also set new standards, but was quickly overtaken by the market.





