
OpenAI's new AI model GLIDE generates images after text input. The results are better than those of other well-known AI models - including OpenAI's DALL-E.
Earlier this year, AI company OpenAI unveiled a multimodal AI model called DALL-E. The AI is trained with image and text data and can therefore generate images that match a text input.
OpenAI then lets the likewise multimodal AI model CLIP sort the generated images according to quality. OpenAI published slimmed-down versions of CLIP, but does not yet offer access to DALL-E.
During the year, AI researchers used CLIP in combination with the deepfake technique GANs (Generative Adversarial Network) to create impressive AI systems that generate or modify images with text input.
Diffusion Models beat GANs
In February, OpenAI published a paper in which the team achieved excellent image generation results for the first time using a new network architecture. Instead of using typical GANs, OpenAI used what it called diffusion models.
These AI models gradually add noise to images during their training and then learn to reverse this process. After AI training, a diffusion model can then ideally generate arbitrary images from pure noise with objects seen during training.
Then in May, OpenAI's image results with Diffusion Models beat GANs' image quality for the first time. In a paper now published, a team from OpenAI shows how a diffusion model with text control outperforms DALL-E and other models.
AI images are becoming more believable
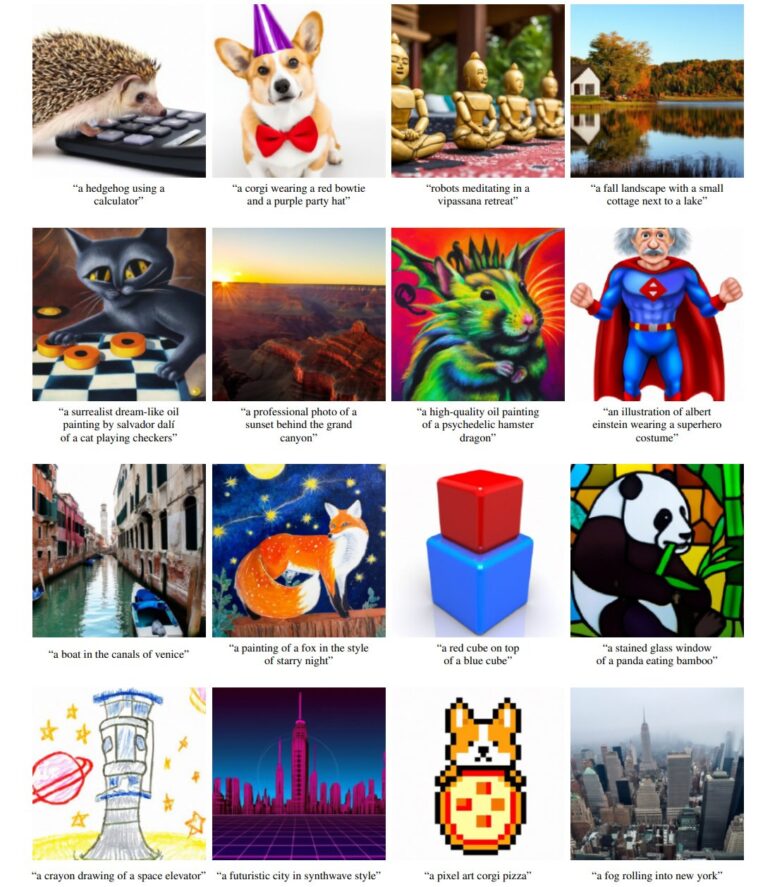
GLIDE stands for "Guided Language to Image Diffusion for Generation and Editing" and, as the name suggests, can use diffusion models to generate and edit images based on text input alone.
The AI model was trained to do this with images and captions. The team also experimented with the integration of CLIP. However, the first variant, which independently learns to generate images from text, produced better results than the one with additional AI quality control through CLIP.

GLIDE can also modify images: Users mark the place they want to change on the image and then describe the change via text. GLIDE then automatically adjusts the image.

All images were generated from a 3.5 billion parameter mesh at a resolution of 64 by 64 pixels and upsampled from a 1.5 billion parameter mesh to 256 by 256 pixels. In a test, people rated the results of GLIDE significantly better than those of DALL-E or other networks.
GLIDE does not produce results for certain text inputs, such as generating a car with square wheels. The model is also slower than GAN alternatives and is therefore not suitable for real-time applications, the researchers write.
OpenAI is holding off on the large GLIDE model for now. However, a smaller 300-million-parameter variant of GLIDE is freely available. The team has additionally trained the published AI model with a heavily filtered dataset for security reasons. The small GLIDE variant cannot generate images of people, for example.
More information and the data is available on GLIDE's Github. GLIDE can also be tested via a Google Colab.





