OpenAI improves GPT-4's mathematical reasoning with a new form of supervision

OpenAI shows an AI model that achieves SOTA in solving some mathematical problems. The underlying process could lead to better language models in general.
In the Let's Verify Step by Step paper, the OpenAI team trained several models based on GPT-4 to solve problems in the MATH dataset. The goal was to compare two variants of feedback processes for training reward models.
Specifically, the team compared "outcome supervision," in which the AI model receives feedback on the final outcome of a task, with "process supervision," in which the model receives feedback on each specific step of reasoning. In practice, the latter process requires human feedback and is therefore costly for large models and diverse tasks - the current work is therefore an investigation that could determine the future direction of OpenAI.
Process supervision: How to avoid alignment taxes
For mathematical tasks, OpenAI has shown that process supervision produces significantly better results for both large and small models, meaning that the models are more often correct and also exhibit a more human-like thought process, according to the team. Hallucinations or logical errors, which are common even in the best models today, can be reduced.
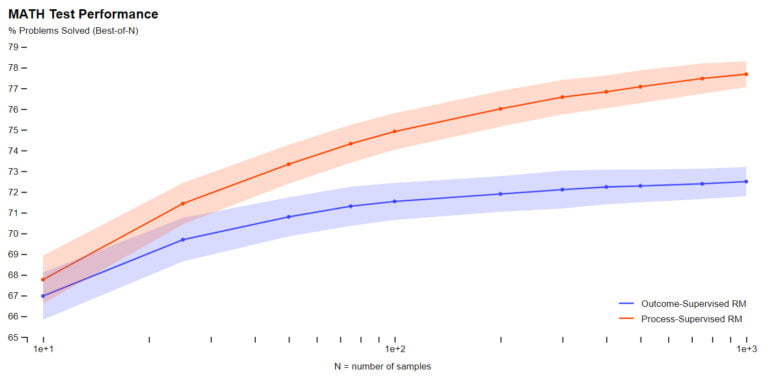
In addition, according to OpenAI, rewarding correct intermediate steps avoids the phenomenon known as alignment tax, in which a model's performance is reduced by its alignment with human values and expectations. In the case of the math tasks tested, the company even finds a negative alignment tax.
"It is unknown how broadly these results will generalize beyond the domain of math, and we consider it important for future work to explore the impact of process supervision in other domains. If these results generalize, we may find that process supervision gives us the best of both worlds – a method that is both more performant and more aligned than outcome supervision."
OpenAI
OpenAI releases human-labeled dataset
The applicability of process supervision to domains outside of mathematics needs to be further explored. To assist in this process, OpenAI has released the PRM800K dataset used for its own model, which contains 800,000 human labels for all intermediate steps in the MATH dataset.
Contributing author and OpenAI co-founder John Schulman recently gave a talk detailing the central role of reward models in shaping desired behaviors in large language models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.