OpenAI looks into complaints about "lazy" ChatGPT with GPT-4

For months, users have been complaining that GPT-4 performance in ChatGPT is getting worse, even with the new Turbo model. OpenAI is looking into this feedback.
Recently, more and more users have complained about bad or incomplete answers, especially when generating code. OpenAI now responds to these complaints on X.
"Model behavior can be unpredictable, and we're looking into fixing it," OpenAI writes.
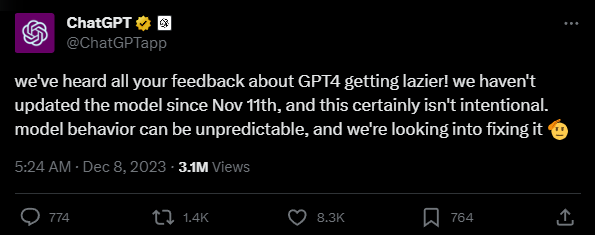
The company does not suspect that the model itself has changed. According to OpenAI, GPT-4 Turbo has not been updated since November 11.
However, the differences in the model's behavior could be very subtle. "Only a subset of prompts may be degraded, and it may take a long time for customers and employees to notice and fix these patterns," OpenAI writes.
The complexity of AI development
In subsequent tweets, OpenAI explained the intricacies of AI training. Different training runs, even with the same data sets, could produce models with significant differences in personality, writing style, denial behavior, evaluation performance, and even political bias.
It is not a "clean industrial process," but rather an "artisanal, multi-person effort" that cannot be compared to simply updating a website. Many people are involved in planning, building, and evaluating new chat models. OpenAI specifically describes "dynamic evaluation" as a "problem".
When releasing a new model we do thorough testing both on offline evaluation metrics and online A/B tests. After receiving all these results, we try to make a data driven decision on whether the new model is an improvement over the previous one for real users.
OpenAI
Complaints about GPT-4 performance degradation started last summer
When OpenAI updated the first model from version 0314 to version 0613 in the summer, some people complained about performance loss.
OpenAI has responded to the criticism by extending the availability of the original GPT-4 model 0314, which was released in March 2023, until at least summer 2024.
It's not yet clear whether performance has degraded, and if so, by how much and in what areas. According to OpenAI, a model update may improve performance in some areas but degrade it in others.
Recently, code benchmarks for GPT-4 Turbo showed that the Turbo model was able to solve fewer code problems, and often only on the second try. One hypothesis behind this performance drop is that GPT-4 Turbo has been further distilled for cost reasons, and the stored and subsequently recalled tasks contained in the original GPT-4 have been lost in the process.
OpenAI itself refers to GPT-4 Turbo as the "smartest" model, a term that is open to interpretation and could refer to the ratio of performance to energy consumption rather than basic problem-solving capability.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.