OpenAI says ChatGPT will always make things up, but it could get better at admitting uncertainty

AI systems like ChatGPT will always make things up, but they may soon get better at recognizing their own uncertainty.
OpenAI says language models will always hallucinate, meaning they'll sometimes generate false or misleading statements, also known as "bullshit." This happens because these systems are trained to predict the next most likely word, not to tell the truth. Since they have no concept of what's true or false, they can produce convincing but inaccurate answers just as easily as correct ones. While that might be fine for creative tasks, it's a real problem when users expect reliable information.
OpenAI breaks down different types of hallucinations. Intrinsic hallucinations directly contradict the prompt, like answering "2" when asked "How many Ds are in DEEPSEEK?" Extrinsic hallucinations go against real-world facts or the model's training data, such as inventing fake quotes or biographies. Then there are "arbitrary fact" hallucinations, which show up when the model tries to answer questions about things rarely or never seen in its training, like specific birthdays or dissertation titles. In those cases, the model just guesses.
To reduce hallucinations, OpenAI says it uses several strategies: reinforcement learning with human feedback, external tools like calculators and databases, and retrieval-augmented generation. Fact-checking subsystems add another layer. Over time, OpenAI wants to build a modular "system of systems" that makes models more reliable and predictable.
Models should admit uncertainty
OpenAI says hallucinations will always be part of language models, but future versions should at least know when they're unsure—and say so. Instead of guessing, models should use outside tools, ask for help, or just stop responding.
That doesn't mean the model truly understands what's true or false, but it does mean it can signal when it's not confident about its own answers. The goal is to make model behavior feel more human. People don't have all the answers, and sometimes it's better to admit not knowing than to just guess. Of course, people still guess from time to time.
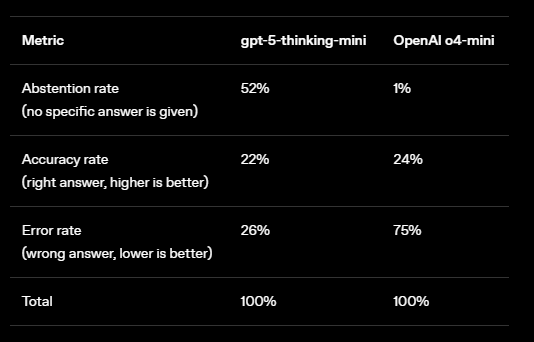
OpenAI points to a deeper issue with how large language models are evaluated. Most benchmarks use strict right-or-wrong scoring and don't give credit for answers like "I don't know." According to OpenAI, this setup encourages models to guess rather than admit uncertainty, which in turn leads to more hallucinations.
That means models that honestly say when they're unsure end up with lower scores than those that always guess, even if they're just making things up. OpenAI calls this an "epidemic," where the system punishes uncertainty and rewards hallucination.
To address this, OpenAI suggests changing the way benchmarks work. Instead of rewarding models for always giving an answer, tasks could require models to respond only when they're confident. Wrong answers would be penalized, while saying "I don't know" wouldn't count against the model. OpenAI says these "confidence thresholds" could offer a more objective way to gauge responsible model behavior, rather than just favoring confident responses.
There's already some progress outside of OpenAI's own benchmarks. A Stanford math professor recently spent a year testing an unsolved problem on OpenAI's models. Earlier versions gave incorrect answers, but the latest model finally admitted it couldn't solve the problem. It also chose not to guess on the toughest question from this year's International Mathematical Olympiad. OpenAI says these improvements should make their way into commercial models in the coming months.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.