OpenAI says top AI models are reaching expert territory on real-world knowledge work

Update –
- Added performance differences depending on the file format
Update September 27, 2025:
One chart from the GDPval paper shows that AI model scores depend a lot on the file format used for their submissions. On plain text tasks, the models have the lowest win rates: Claude Opus 4.1 lands at just 14 percent, and GPT-5 at 22 percent.
The results look very different for other formats. For PDFs, Claude jumps to a 46 percent win rate. On Excel files (xlsx), it's 45 percent, and for PowerPoint presentations (pptx), 48 percent. In the "other" category—which includes various other formats—Claude Opus 4.1 matches human professionals at 50 percent.
GPT-5 shows the same trend: its scores for structured or visual formats like xlsx (36 percent) and "other" (49 percent) are much higher than for "pure text."
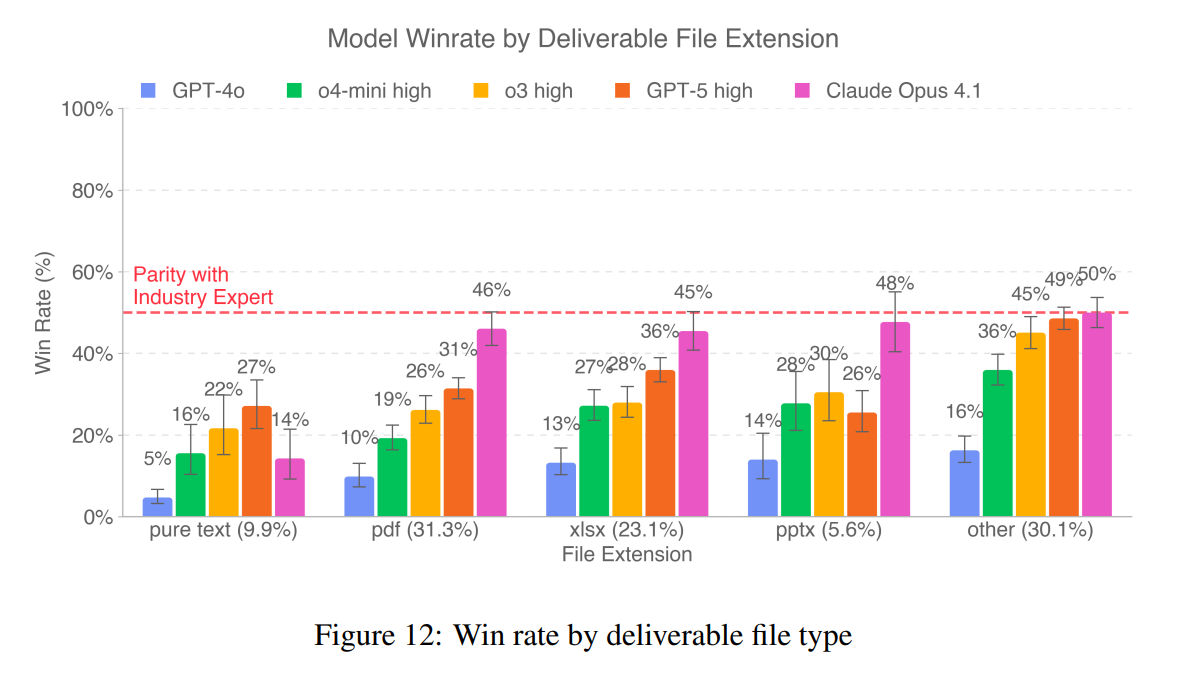
OpenAI doesn't give a reason for these differences. It's likely that human reviewers are influenced by things like layout and visual design. Models can score points with neat formatting, clear structure, and strong visuals in presentations, spreadsheets, or PDFs, even when the actual content isn't better. With plain text, that advantage disappears, and the AI has to compete directly with human-level writing and reasoning.
It's also worth noting that PDF, Excel, and "other" formats together make up over 80 percent of all deliverables. That helps explain why models like Claude Opus 4.1 end up with fairly high overall win rates, even though they still lag far behind humans on plain text tasks.
Original article from September 26, 2025:
GDPval sets a new standard for benchmarking AI on real-world knowledge work, with 1,320 tasks spanning 44 professions, all reviewed by industry experts.
OpenAI has launched GDPval, a new benchmark built to see how well AI performs on actual knowledge work. The first version covers 44 professions from nine major industries, each making up more than 5 percent of US GDP.
To pick the roles, OpenAI grabbed the highest-paying jobs in these sectors and filtered them through the O*NET database, a resource developed by the US Department of Labor that catalogs detailed information about occupations, making sure at least 60 percent of the work is non-physical. The list is based on Bureau of Labor Statistics (May 2024) numbers, according to OpenAI.
The task set spans technology, nursing, law, software development, journalism, and more. Each task was created by professionals averaging 14 years of experience, and all are based on real-world work products like legal briefs, care plans, and technical presentations.
Real tasks, real requirements
Unlike traditional AI benchmarks that rely on simple text prompts, GDPval tasks require additional materials and deliverables in complex formats. For instance, a mechanical engineer might be asked to design a test bench for a cable winding system, deliver a 3D model, and put together a PowerPoint presentation, all based on technical specs.
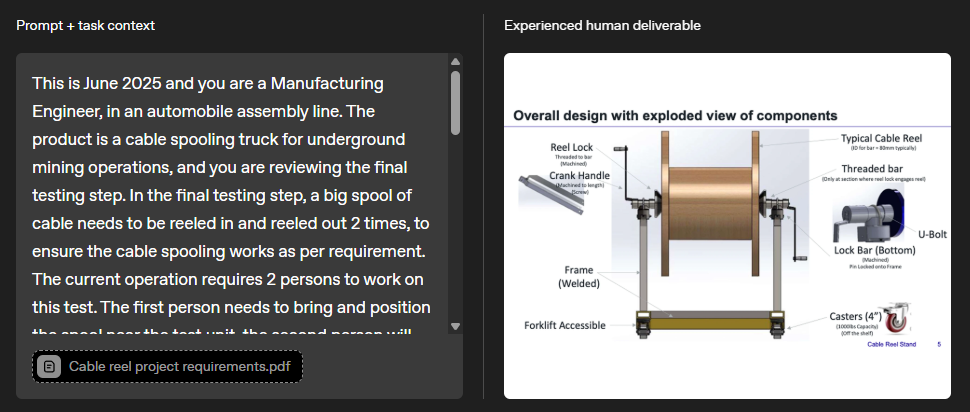
Every result is rated by industry experts in blind tests, directly comparing AI outputs with human reference solutions - and scoring them as "better," "as good as," or "worse than."
OpenAI also built an experimental AI-based review assistant to simulate human scoring. According to the paper, each task was reviewed about five times through peer checks, extra expert reviews, and model-based validation.
Leading models are closing in on expert performance
Early results show top models like GPT-5 and Claude Opus 4.1 are getting close to expert-level performance. In about half of the 220 gold-standard tasks published so far, experts rated the AI's work as equal to or better than the human benchmark.
GPT-5 shows major gains over GPT-4o, which launched in spring 2024. Depending on the metric, GPT-5's scores have doubled or even tripled. Claude Opus 4.1 goes further, with results rated as good as or better than human output in nearly half of all tasks. Claude tends to stand out in aesthetics and formatting, while GPT-5 leads in expertise and accuracy, OpenAI claims.
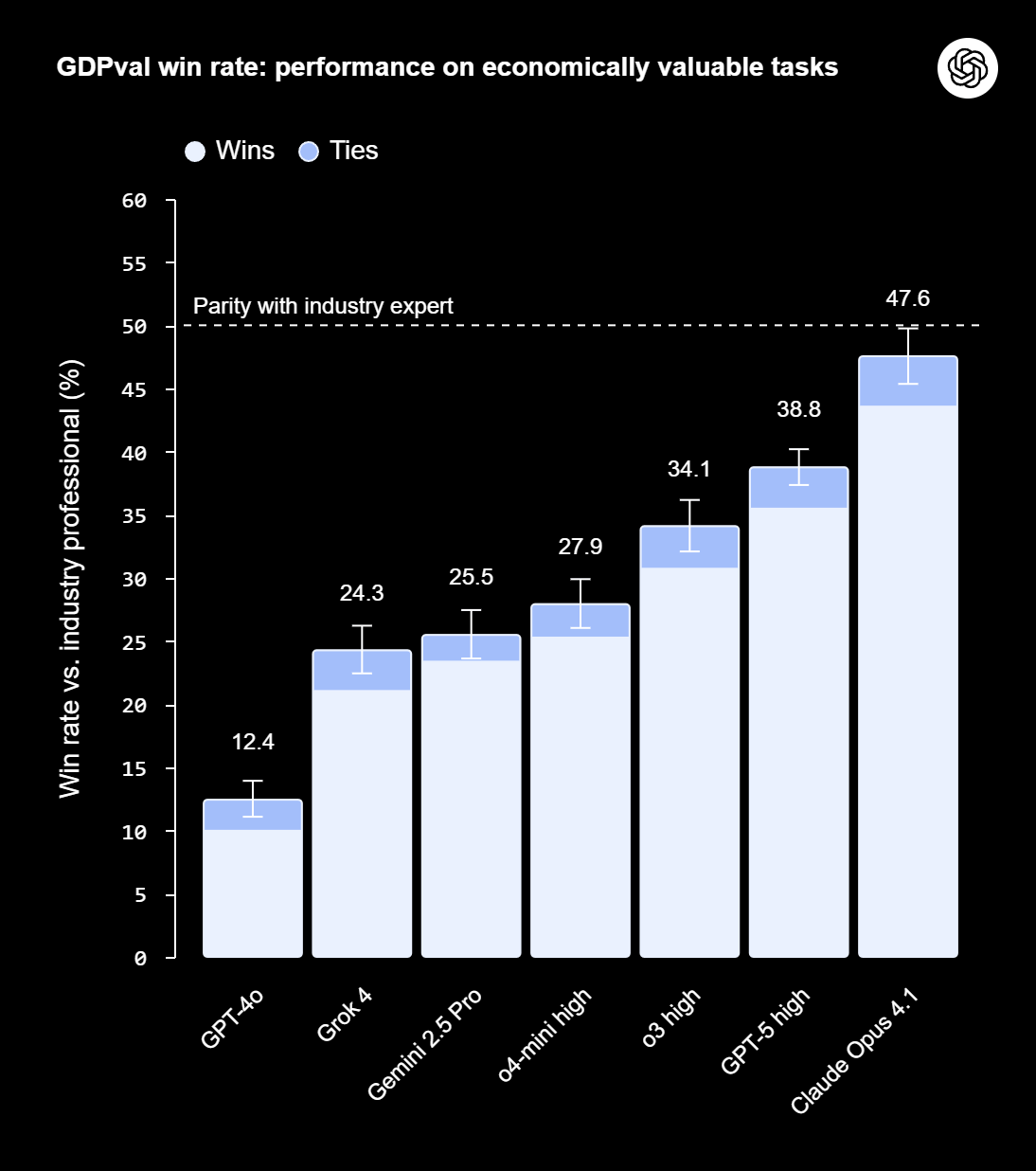
OpenAI also points to big efficiency gains. The models completed tasks about 100 times faster and 100 times cheaper than human experts, if you count just inference time and API costs. The company expects that having AI take the first pass could save time and money, though real-world workflows still need human review, iteration, and integration.
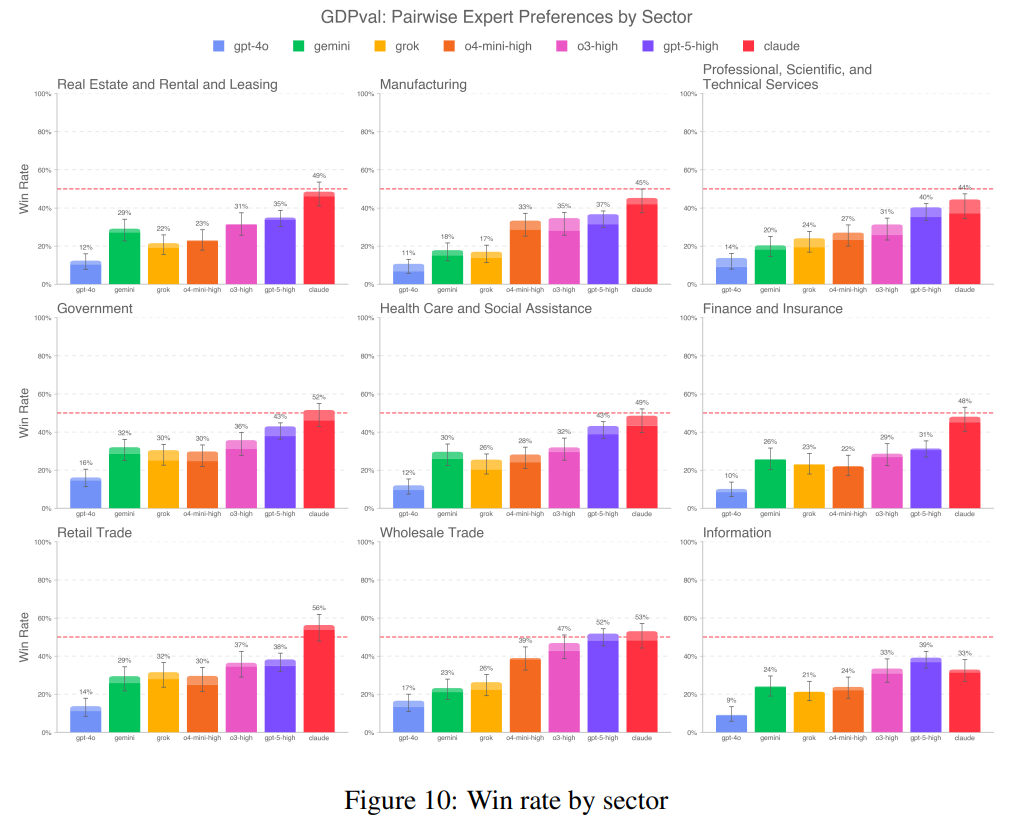
Still not a true workplace simulation
Right now, GDPval sticks to "one-shot" tasks: models get just one chance at each assignment, with no feedback, context building, or iteration. The tasks don't include the kind of real-world ambiguity that comes with unclear requirements or back-and-forth with colleagues and clients. Instead, the benchmark only tests how models handle isolated, computer-based steps. But actual jobs are a lot more than just a series of discrete tasks.
OpenAI is careful to point out that current AI models aren't replacing entire jobs. The company says they're best at automating repetitive, clearly structured tasks. The test set is also fairly limited, with only about 30 tasks per job across the 44 professions. More detail is in the paper.
OpenAI says future versions of GDPval will move closer to realistic work conditions, with more interactive tasks and built-in ambiguity or feedback loops. The long-term goal is to systematically track AI's economic impact and see how it's changing the labor market. If you want to pitch in with tasks or evaluations, you can sign up here or, for OpenAI customers, here.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.