OpenAI tackles AI propaganda generated with tools like ChatGPT

A new paper published by OpenAI and partners describes potential societal risks of large language models related to disinformation and propaganda.
When OpenAI unveiled GPT2 in 2019, it also addressed the societal risks of large language models: the AI model, it said at the time, was too dangerous to release lightly because it could be used to generate Fake News en masse.
Of course, GPT-2 was then released relatively quickly and even more powerful language models appeared, some of which are open source. With ChatGPT, OpenAI has now launched the most powerful language model to date that can be easily used by humans - for free, but that could change.
Although ChatGPT is heavily moderated, it is unlikely to prevent misuse, e.g., in an educational context, for purely machine-generated pseudo-blogs or spam in comments. Moreover, ChatGPT inadvertently generates Fake News itself by inventing information in some responses.
In short, the AI world has changed massively since GPT-2, and probably so has OpenAI, which has had to think and act more commercially at least since Microsoft became a major investor.
OpenAI investigates how to counter AI propaganda
Of course, as a leading provider of commercial language models, OpenAI must continue to address their security and moderation. In the interest of society, but also to protect its own business model. Otherwise, there is a threat of overly harsh government intervention, for example, which would impair development.
In a new paper published by OpenAI with Georgetown University's Center for Security and Emerging Technology and the Stanford Internet Observatory, OpenAI presents a framework for preemptive options against AI-powered disinformation campaigns.
The framework considers the impact on the development and use of language models at different stages (model construction, access to the model, content dissemination, belief formation) by different actors.
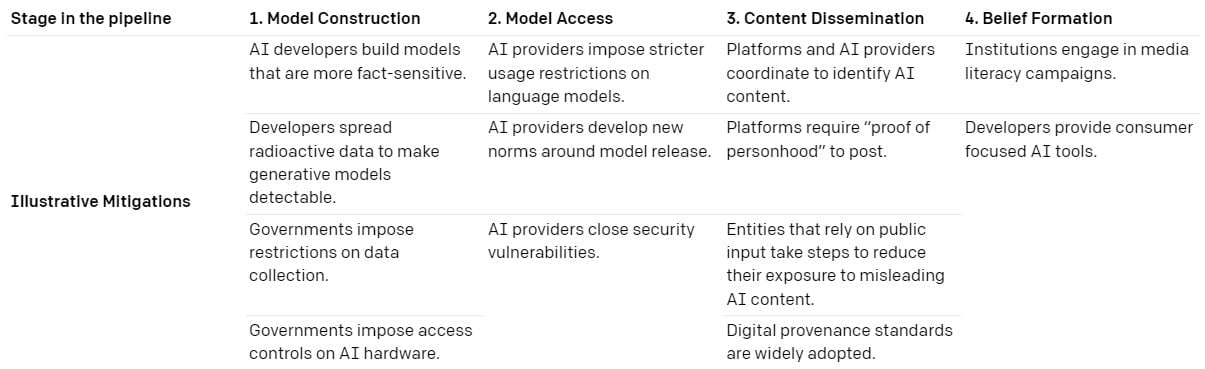
However, just because mitigations exist, they are not per se desirable or implementable. The paper does not evaluate individual mitigations, but instead poses four guiding questions to policymakers:
- Technical Feasibility: Is the proposed mitigation technically feasible? Does it require significant changes to technical infrastructure?
- Social Feasibility: Is the mitigation feasible from a political, legal, and institutional perspective? Does it require costly coordination, are key actors incentivized to implement it, and is it actionable under existing law, regulation, and industry standards?
- Downside Risk: What are the potential negative impacts of the mitigation, and how significant are they?
- Impact: How effective would a proposed mitigation be at reducing the threat?
Content costs approach zero
The research team sees risks in the fact that widely used language models could automate disinformation and significantly reduce the cost of propaganda content. Corresponding campaigns would be easier to scale with AI and would enable new tactics, such as real-time generation of propagandistic content with chatbots.
In addition, AI could be the better propagandist and "generate more impactful or persuasive messaging." It could also add variety to propagandistic messages and make it more difficult to debunk propaganda compared to copy-pasted messages on social networks.
Our bottom-line judgment is that language models will be useful for propagandists and will likely transform online influence operations. Even if the most advanced models are kept private or controlled through application programming interface (API) access, propagandists will likely gravitate towards open-source alternatives and nation states may invest in the technology themselves.
OpenAI
According to the research team, there are also many unknown variables: Which actors will invest where, what emerging capabilities reside in language models, how easy and public will it be to use these models, and will new norms emerge that could deter AI propagandists?
The paper is therefore "far from the final word," the team said, and rather serves as a basis for further discussion.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.