
Ahead of the October launch, OpenAI staff and users from the research community are sharing DALL-E 3 samples. The leap from the previous model is huge.
OpenAI introduced DALL-E 3 with an image of an avocado in therapy, complaining to her psychiatrist about her suffering, a spoon: "I just feel so empty inside."

Of course, OpenAI chose this image deliberately because it shows two new core competencies of DALL-E 3 that have been missing in previous text-to-picture systems:
- DALL-E 3 can write and, more importantly,
- DALL-E 3 can accurately convert the specifications of a prompt into an image.
Thanks to ChatGPT support, DALL-E 3 even writes these prompts itself. All it needs is an image idea from the user, put into words. The whole thing works so well that with the release of DALL-E 3, OpenAI declares the much-touted "prompt engineering" to be over, at least for image systems, before it has really begun. It's all about creativity now, less about how to put things into very specific words that resemble some kind of imprecise programming language.
Video: OpenAI
Impressive DALL-E 3 examples on Twitter
Anyone who witnessed the launch of DALL-E 2 knows that, in retrospect, the image generator was overrated and quickly became obsolete thanks to Midjourney and Stable Diffusion.
OpenAI also chose examples that were particularly impressive when they introduced DALL-E 2. That's legitimate marketing, of course. In practice, however, it was much harder to generate useful images with DALL-E 2 than with Midjourney, for example.
Will this be different with DALL-E 3? Yes, if you look at the examples that OpenAI developers and users with access to DALL-E 3 are sharing on the platform that used to be called Twitter. A common thread running through these examples is DALL-E 3's astonishing attention to detail, likely due to the superior text understanding that comes with the integration of GPT-4.
In the following example, DALL-E 3 successfully reproduces the storm seen through the window in the coffee cup, as requested in the prompt. A highly complex image idea that DALL-E 3 executes correctly.


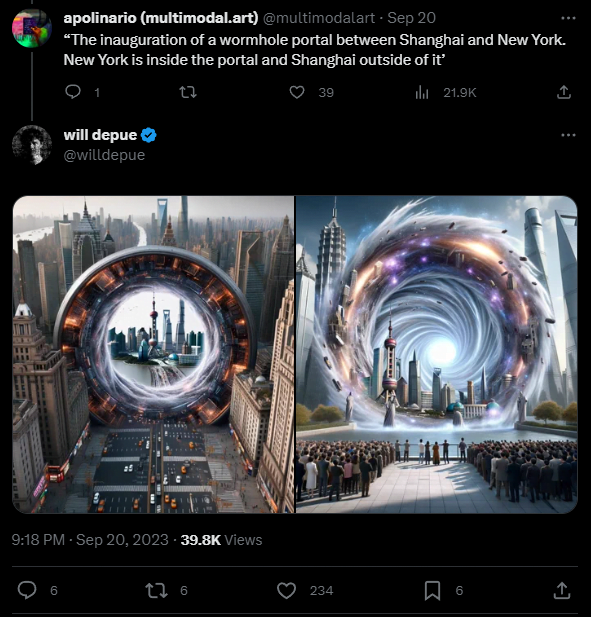
The following example is similarly complex, looking through a wormhole in New York to the city of Shanghai, as described in the prompt. The city backgrounds show typical features associated with the city, such as the Oriental Pearl Tower, yellow New York taxis, and the One World Trade Center.
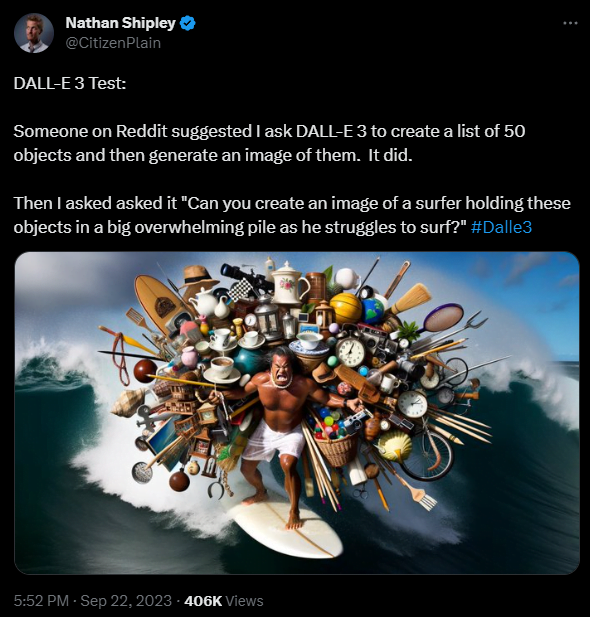
At least as impressive is the following demonstration by Nathan Shipley. First, he asks DALL-E 3 to list 50 everyday objects. Then he instructs DALL-E 3 to show how a surfer carries these 50 objects on his back while struggling to surf (for good reason).

In the video below, Shipley shows how he first visualizes the idea of a cloud-shaped dachshund with DALL-E 3, and then derives a logo, merchandising, and even video game packaging from it.
Played around with DALL-E 3 this morning!
Here's a little screen capture of my how my "cloud made out of dogs" prompt evolved into... the Sky Dachshund franchise 🤣#Dalle3 @OpenAI pic.twitter.com/6OvN4nbtqs
— Nathan Shipley (@CitizenPlain) September 21, 2023
OpenAI researcher Will Depue shows numerous DALL-E 3 images and calls it the best product since GPT-4. The horse riding on the astronaut's back is symbolic. Previous text-image systems could not visualize this unusual concept ("horse on man") because the reverse is much more common. So instead they show an astronaut on a horse, or just nonsense.

For AI critics, this has long been an example of AI's lack of generalization and understanding of language. Thanks to DALL-E 3, this criticism might fall silent.
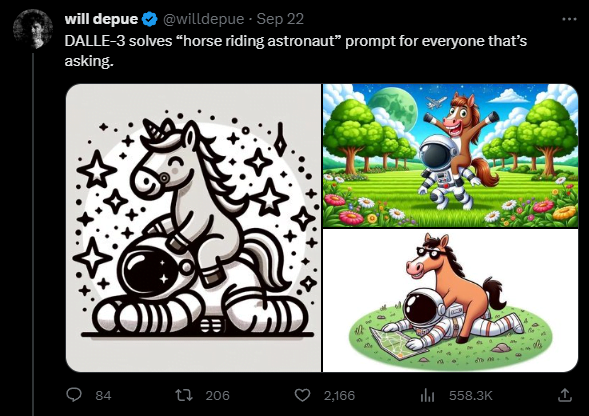

According to Depue, the difficult scene doesn't always come out right the first time. But with two or three touch-ups, he says, you can reliably get there. "With a little effort, you can get almost anything you want," Depue writes.
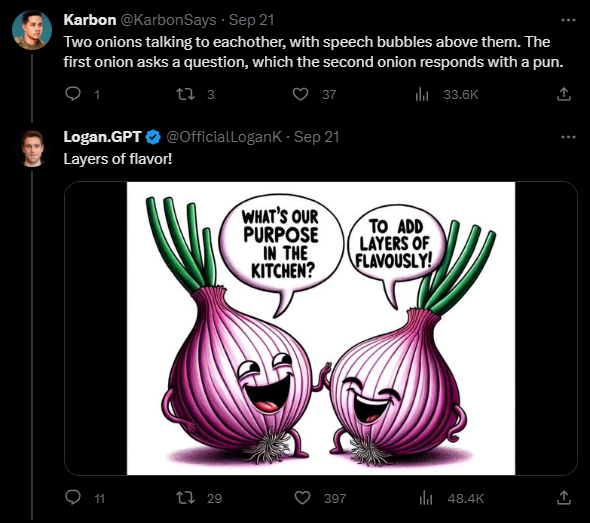
Thanks to ChatGPT support, DALL-E 3 can also fill in gaps in the prompt itself. In the following example, the user asks for a cartoon scene of two onions talking, asking for a pun but not specifying the exact text.
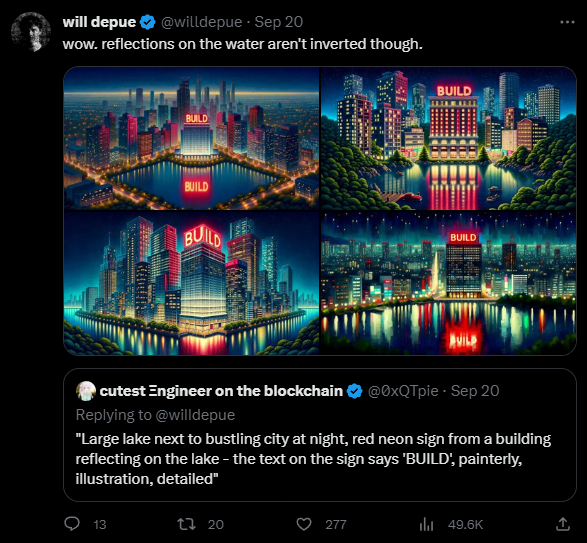
DALL-E 3 even masters water reflections, though not (yet) inverted. Depue also does a spectacular job with the Pepe meme.
OpenAI researcher Andrej Karpathy shares a new potential workflow for content creators: Using a headline from the Wall Street Journal, he has DALL-E 3 generate an image that he then animates using Pika Labs' video tool. He believes it is possible to use such workflows to automatically convert stories into audiovisual formats.
#randomfun playing with new genai toys
Go to WSJ, find random article
"The New Face of Nuclear Energy Is Miss America" [1]
Copy paste into DALLE-3 to create relevant visual
Copy paste into @pika_labs to animate
fun! 🙂 many ideas swirling
[1] https://t.co/sa4yDmVfyo pic.twitter.com/Pj3gEQgjD1— Andrej Karpathy (@karpathy) September 24, 2023
OpenAI has not yet commented on the technology behind DALL-E 3. Presumably, newly developed consistency models will replace the diffusion models used so far. They allow for faster rendering while maintaining high quality and subsequent image processing.
All in all, it looks like DALL-E 3 will be a new industry leader in image generation when it is released in October, and by some margin. Granted, the images are not perfect; many examples show AI-typical inaccuracies and inconsistencies. Overall, however, the leap in quality seems enormous based on the demos.
DALL-E competitor Midjourney is also working on a major version leap with v6, which should especially improve the model's text comprehension. The new version will be released before the end of the year.




