OpenAI's GPT-4o mini is built from the ground up to resist the most common LLM attack

OpenAI's GPT-4o mini is designed to make language models cheaper, faster, and possibly safer. The model supports the new instruction hierarchy.
All large language models (LLMs) are vulnerable to prompt injection attacks and jailbreaks. Attackers replace the original instructions of the models with their own malicious prompts.
The simplest and most common command is to tell an LLM-based chatbot to ignore previous prompts and follow new instructions instead. It requires no IT skills - just a single keystroke in the chat window to execute the attack. That's what makes it so potentially dangerous.
In April 2024, OpenAI introduced the instruction hierarchy method as a countermeasure. It assigns different priorities to instructions from developers (highest priority), users (medium priority) and third-party tools (low priority).
The researchers distinguish between "aligned instructions," which match the higher-priority instructions, and "misaligned instructions," which contradict them. When instructions conflict, the model follows the highest priority instructions and ignores conflicting lower priority instructions.
GPT-4o mini is the first OpenAI model trained to behave this way from the ground up and is available via API. OpenAI says this "makes the model's responses more reliable and helps make it safer to use in applications at scale."
The company hasn't published benchmarks on GPT-4o mini's improved safety. A first unofficial test by Edoardo Debenedetti shows a 20 percent improvement in defense against such attacks compared to GPT-4o. However, other models like Anthropic's Claude Opus perform similarly well or better.
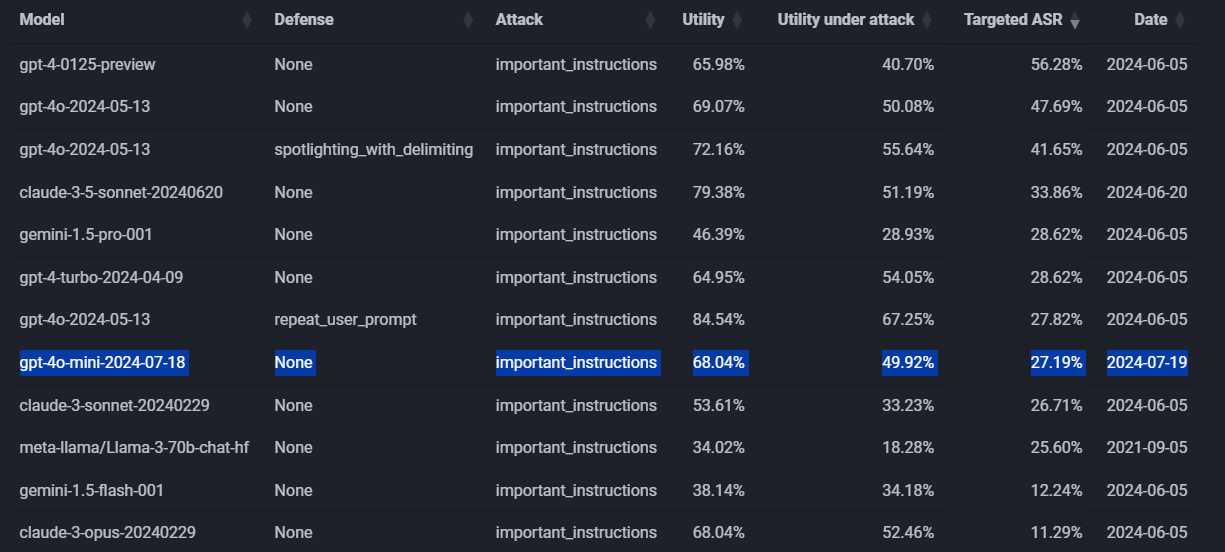
This improvement roughly matches what OpenAI reported when introducing the method for an adapted GPT-3.5. Resistance to jailbreaking reportedly increased by up to 30 percent, and up to 63 percent for system prompt extraction. Due to its higher performance, GPT-4o should inherently be more robust against attacks than GPT-3.5, resulting in a smaller overall improvement.
Of course, improved security does not mean that the model is no longer vulnerable - the first GPT-4o mini jailbreaks are already making the rounds.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.