
Researchers from Tsinghua University, Shanghai Artificial Intelligence Laboratory, and 01.AI have developed a new framework called OpenChat to improve open-source language models with mixed data quality.
Open-source language models such as LLaMA and LLaMA2, which allow anyone to inspect and understand the program code, are often refined and optimized using special techniques such as supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT).
However, these techniques assume that all data used is of the same quality. In practice, however, a data set typically consists of a mixture of optimal and relatively poor data. This can hurt the performance of language models.
To solve this problem, OpenChat uses a new method called Conditioned RLFT (C-RLFT). This method treats different data sources as different classes that serve as coarse reward labels, without the need to specifically label preferred data. Simply put, the system learns that some data is excellent while other data is relatively poor and weights it accordingly without having to explicitly label the data.
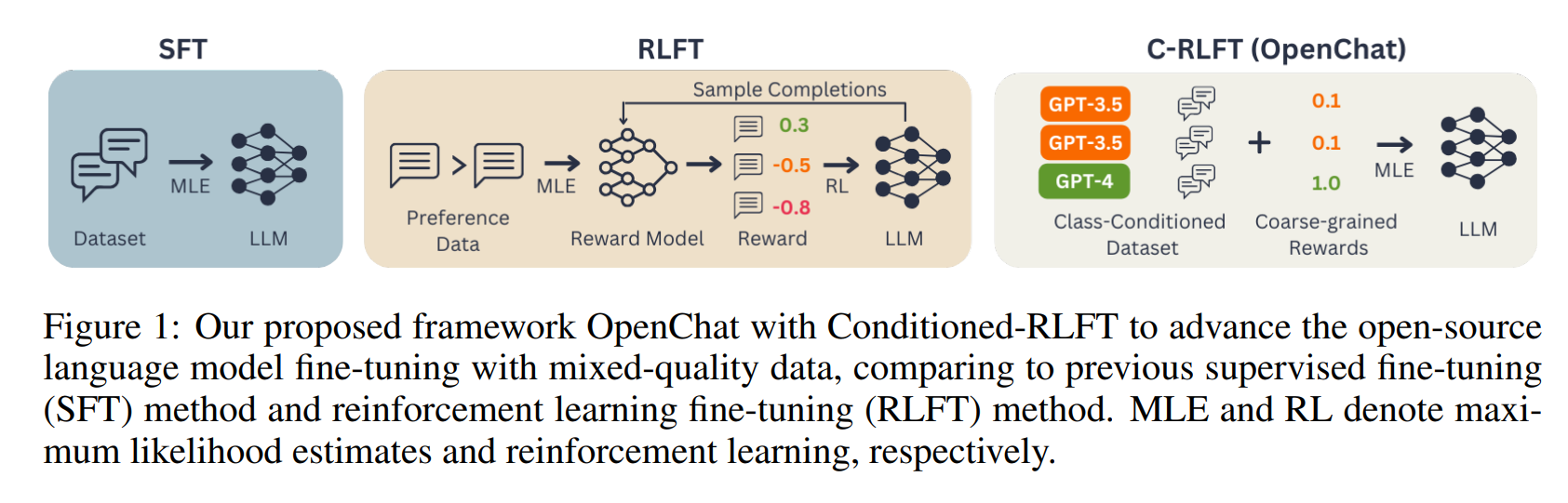
Because C-RLFT does not require complex reinforcement learning or expensive human feedback, it is relatively easy to implement. According to the researchers, one-step RL-free supervised learning is sufficient, in which the AI learns from a few examples with correct answers without having to resort to trial-and-error methods such as reinforcement learning. This saves time and compute.
C-RLFT shows potential in benchmarks
C-RLFT has several advantages over other methods. It is less dependent on data quality because it can work with a mixture of good and bad data. The method is easier to implement than others because it does not require complex learning and evaluation processes, and it is robust because it specifically uses different data qualities. Because it does not rely on expensive human feedback, C-RLFT is also cost-effective.
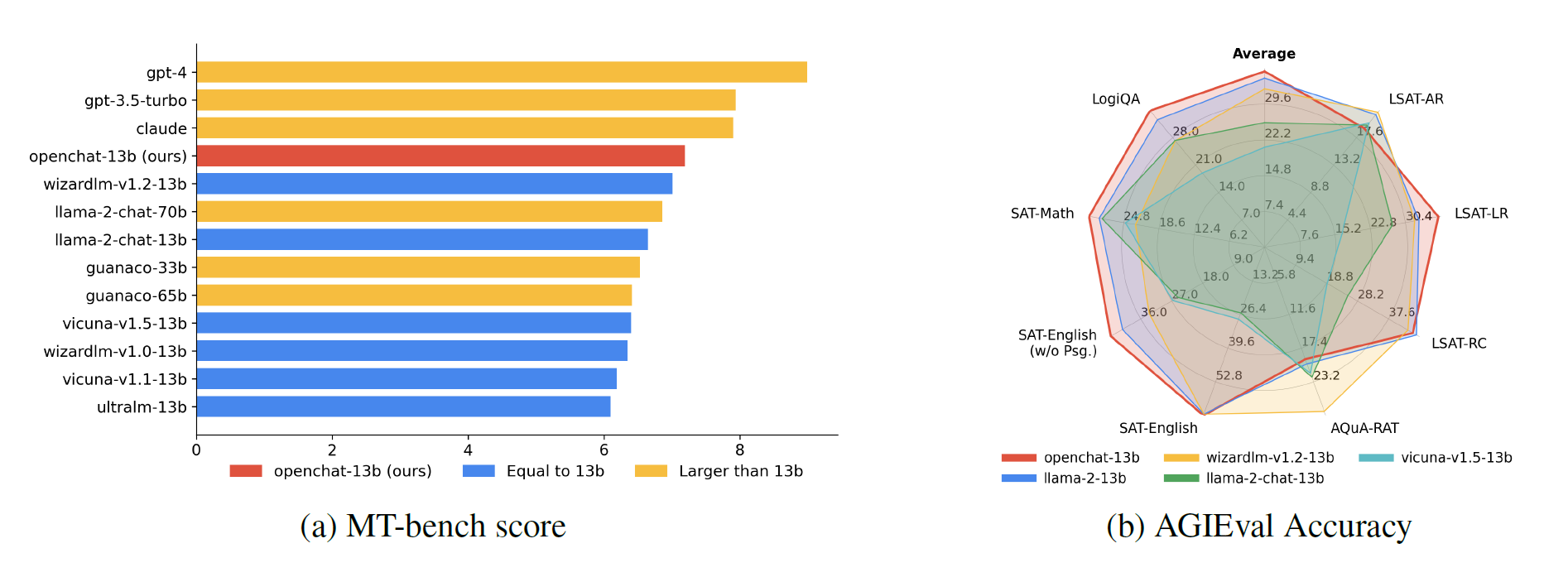
In initial tests, the OpenChat 13b model refined with C-RLFT outperforms all other language models tested and can even outperform much larger models such as Llama 2 70B on the MT bench.
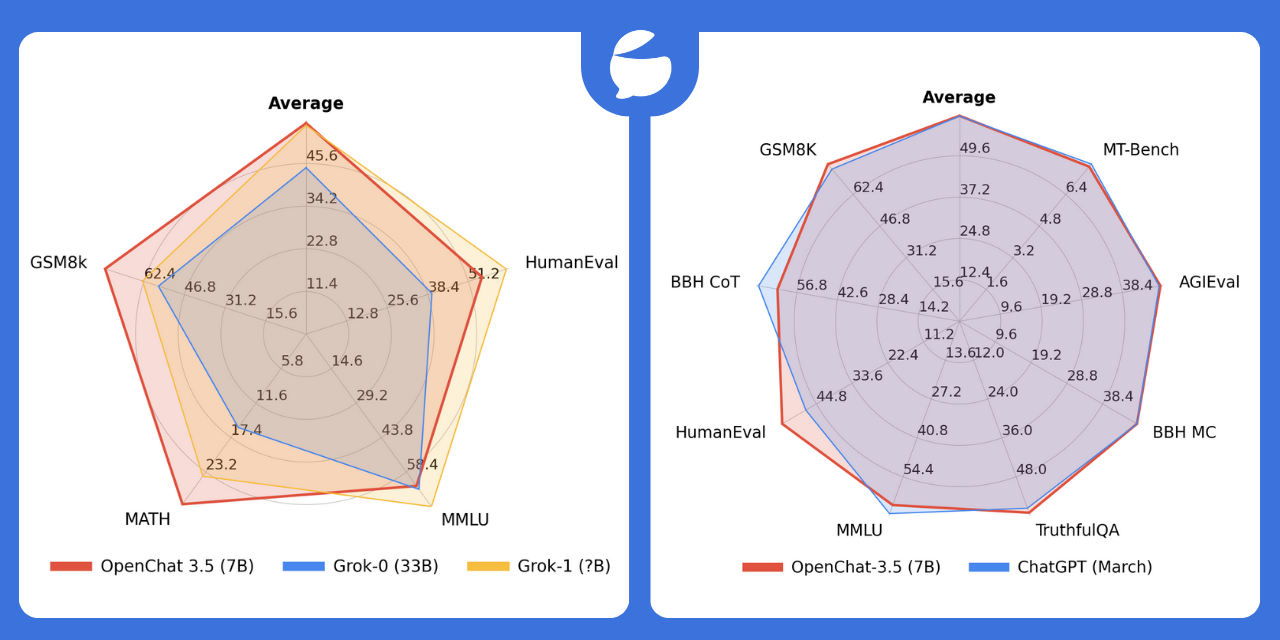
The benchmarks above are from the C-RLFT paper from late September. According to the research team, the OpenChat 3.5-7B model with 8K context window released in early November was even able to outperform ChatGPT in some benchmarks.
The researchers see room for improvement. For example, the distribution of rewards across different data sources could be further refined. The method could also be used in the future to improve the capabilities of language models in other areas, such as logical reasoning.

The OpenChat framework and all associated data and models are publicly available on Github. An online demo is available here. The OpenChat v3 models are based on Llama and can be used commercially under the Llama license.




