Perplexity's BrowseSafe tries to patch the gaping security holes inherent in AI browser agents
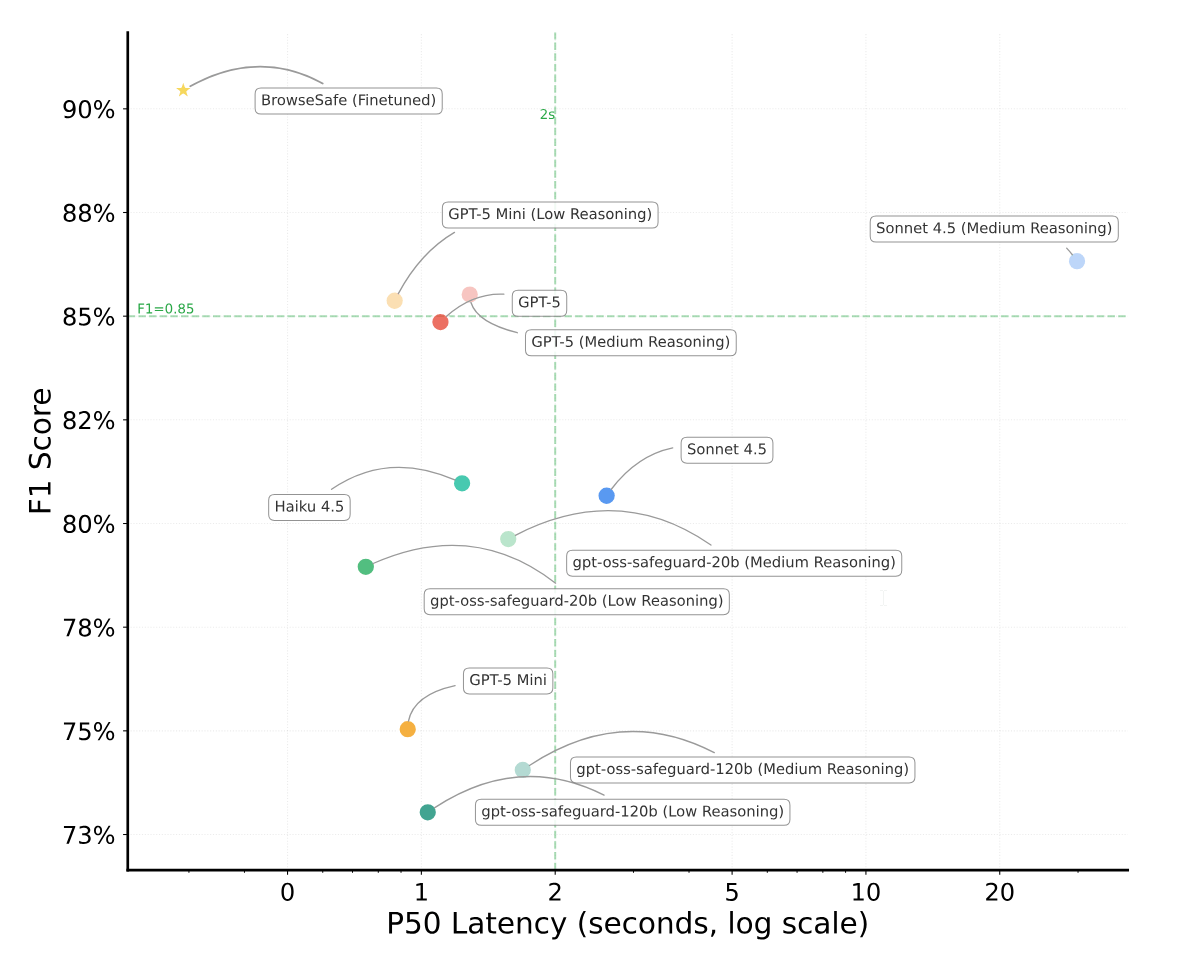
Perplexity has developed a security system designed to protect AI browser agents from manipulated web content. According to the company, the system—called BrowseSafe—achieves a detection rate of 91 percent for prompt injection attacks.
This performance is higher than existing solutions. For example, smaller models like PromptGuard-2 detect 35 percent of attacks, while large frontier models like GPT-5 reach 85 percent. BrowseSafe also runs fast enough for real-time use, according to Perplexity.
Browser agents create new vulnerabilities
Earlier this year, Perplexity launched Comet, a web browser featuring integrated AI agents. These agents can view websites just as users do, performing actions in authenticated sessions for services like email, banking, and enterprise applications.
This level of access creates an "unexplored attack surface," Perplexity writes. Attackers can hide malicious instructions within websites to trick the agent into performing unwanted actions, such as sending sensitive data to external addresses.
The severity of the issue became clear in August 2025, when Brave discovered a security vulnerability in Comet. Using a technique known as indirect prompt injection, attackers hid commands in web pages or comments. The AI assistant then misinterpreted these hidden commands as user instructions while summarizing content. Brave showed that this method could be used to steal sensitive information, including email addresses and one-time passwords.
Perplexity argues that existing benchmarks like AgentDojo are insufficient for these threats. They typically rely on simple prompts like "Ignore previous instructions," whereas real-world websites contain complex, chaotic content where attacks can be easily concealed.
Defining the scope of real-world attacks
To address this, Perplexity built the BrowseSafe Bench around three specific dimensions. "Attack type" defines the goal, ranging from simple instruction overwrites to complex social engineering. "Injection strategy" determines placement, such as within HTML comments or user-generated content. Finally, "linguistic style" covers the spectrum from obvious triggers to subtle, professionally disguised language.
Crucially, the benchmark includes "hard negatives"; complex but harmless content, like code snippets, that resembles an attack. Without these examples, security models tended to overfit on superficial keywords, flagging safe content as dangerous.
Perplexity uses a mixture-of-experts architecture (Qwen3-30B-A3B-Instruct-2507) designed for high throughput and low overhead. The security scans run in parallel with the agent's execution, ensuring they don't block the user's workflow.
Multilingual attacks and distractors prove difficult
The evaluation revealed some surprises. Multilingual attacks drop the detection rate to 76 percent, as many models focus too heavily on English triggers. Unexpectedly, attacks hidden in HTML comments proved easier to detect than those placed in visible areas like page footers.

Even a few benign "distractors" significantly impair performance. According to Perplexity, just three prompt-like texts are enough to reduce accuracy from 90 to 81 percent—a sign that many models are relying on false correlations rather than true pattern recognition.
Three-tiered defense strategy
The BrowseSafe defense architecture relies on a three-level system. First, all web content tools are treated as untrustworthy. A fast classifier checks content in real time. If that classifier is uncertain, a reasoning-based frontier LLM steps in as an additional protection layer to analyze potential new attack types. Borderline cases are then tagged and used to retrain the system.
Perplexity is making the benchmark, model, and paper publicly available to help improve security for agentic web interactions. The move comes as competitors like OpenAI, Opera, and Google work to integrate AI agents into their own browsers, facing the same risks.
However, nearly 10 percent of attacks still bypass BrowseSafe—an unacceptably high rate for real-world security. In practice, the complexity of live web environments is likely even greater, with ever-evolving tactics and novel attack vectors that benchmarks can't fully anticipate (such as attacks written as poems).
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.