Probe3D: Study examines how well AI models understand the third dimension

A new study examines whether and how well multimodal AI models understand the 3D structure of scenes and objects.
Researchers from the University of Michigan and Google Research investigated the 3D awareness of multimodal models. The goal was to understand how well the representations learned by these models capture the 3D structure of our world.
According to the team, 3D awareness can be measured by two key capabilities: Can the models reconstruct the visible 3D surface from a single image, i.e., infer depth and surface information? Are the representations consistent across multiple views of the same object or scene?
The results show that some models can encode depth and surface information without explicit training. In particular, the self-monitoring models DINO and DINOv2 and the text-driven diffusion model StableDiffusion performed well. Models trained with vision-language pre-training, such as CLIP, were an exception. They captured very little 3D information.
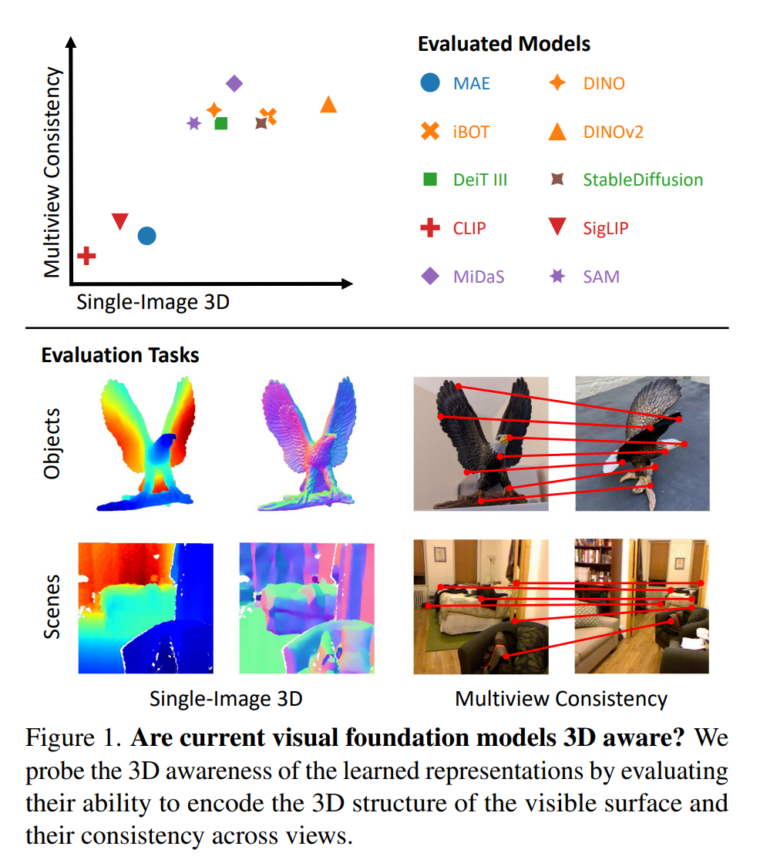
Multimodal models likely not learning 3D consistent representations
In terms of consistency across multiple viewpoints, all the models tested showed weaknesses. While they were still able to produce accurate mappings between image regions with small changes in viewing angle, their performance dropped sharply with larger changes in viewing angle.
The researchers conclude that the models learned representations that are view-consistent, not 3D consistent. The researchers hope their findings will spark more interest in this topic, especially given the impressive progress in photorealistic image and video synthesis by generative AI models such as OpenAI's Sora. 3D understanding also includes the ability to infer spatial relationships and make predictions about deformation and dynamics - whether Sora has these capabilities will be the subject of future work.
The code and results are available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.