Reasoning models like Deepseek-R1 and OpenAI o1 suffer from 'underthinking', study finds

Chinese researchers have discovered why AI models often struggle with complex reasoning tasks: They tend to drop promising solutions too quickly, leading to wasted computing power and lower accuracy.
Researchers from Tencent AI Lab, Soochow University, and Shanghai Jiao Tong University show that reasoning models like OpenAI's o1 frequently jump between different problem-solving approaches, often starting fresh with phrases like "Alternatively…" This behavior becomes more noticeable as tasks get harder, with models using more computing power when they arrive at wrong answers.

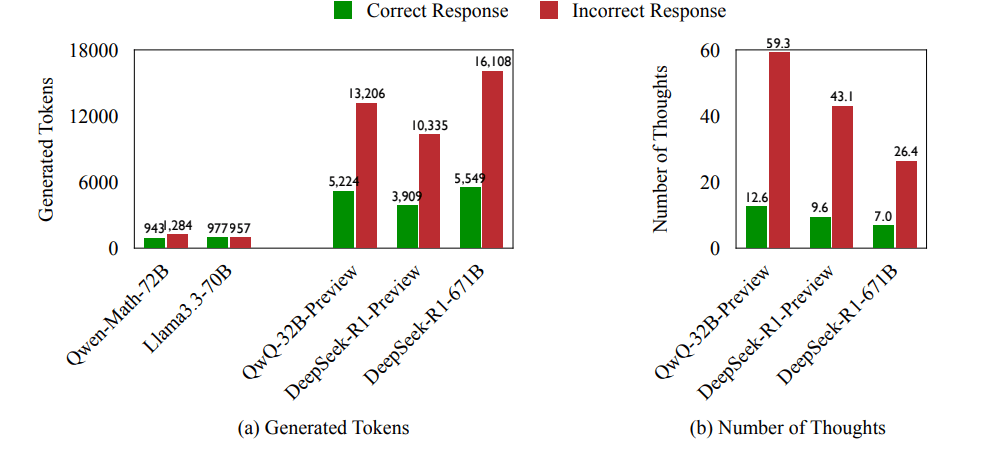
The team found that 70 percent of incorrect answers contained at least one valid line of reasoning that wasn't fully explored. When models gave wrong answers, they used 225 percent more computing tokens and changed strategies 418 percent more often compared to correct solutions.
To track this problem, the researchers created a metric that measures how efficiently models use their computing tokens when they get answers wrong. Specifically, they looked at how many tokens actually contribute to finding the right solution before the model switches to a different approach.
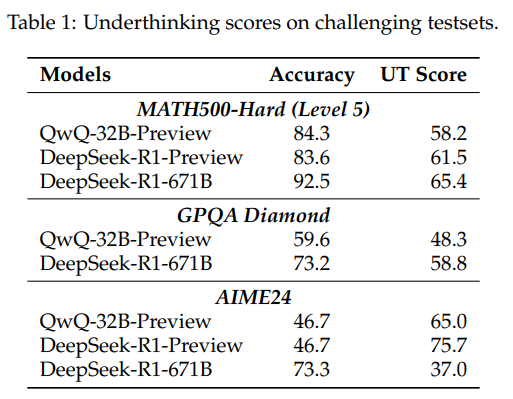
The team tested this using three challenging sets of problems: math competition questions, college physics problems, and chemistry tasks. They wanted to see how models like QwQ-32B-Preview and Deepseek-R1-671B handle complex reasoning. The results showed that o1-style models often waste tokens by jumping between different approaches too quickly. Surprisingly, models that get more answers right don't necessarily use their tokens more efficiently.
Making models stick to their ideas
To address underthinking, the research team developed what they call a "thought switching penalty" (TIP). It works by adjusting the probability scores for certain tokens - the building blocks models use to form responses.
When the model considers using words that signal a strategy change, like "Alternatively", TIP punishes these choices by reducing their likelihood. This pushes the model to explore its current line of reasoning more thoroughly before jumping to a different approach.
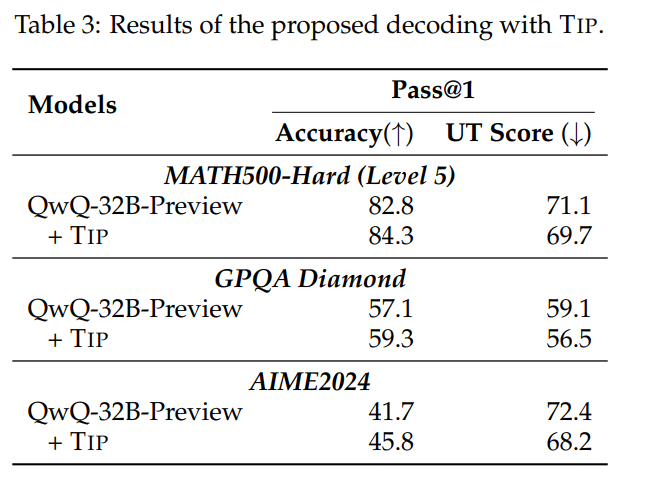
When using TIP, the QwQ-32B-Preview model solved more MATH500-Hard problems correctly - improving from 82.8 to 84.3 percent accuracy - and showed more consistent reasoning. The team saw similar improvements when they tried it on other tough problem sets like GPQA Diamond and AIME2024.
These results point to something interesting: getting AI to reason well isn't just about having more computing power. Models also need to learn when to stick with a promising idea. Looking ahead, the research team wants to find ways for models to manage their own problem-solving approach better - knowing when to keep going with an idea and when it's actually time to try something new.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.