Salesforce's CRM benchmark finds AI agents struggle in real-world business scenarios

Salesforce's new CRMArena-Pro benchmark reveals major challenges for AI agents in business contexts. Even top models like Gemini 2.5 Pro manage just a 58 percent success rate on single turns. When the dialog gets longer, performance drops to 35 percent.
CRMArena-Pro is designed to test how well large language models (LLMs) can function as agents in real-world business settings, especially for CRM tasks like sales, customer service, and pricing. The benchmark builds on the original CRMArena, adding more business functions, multi-turn dialogs, and tests for data privacy. Using synthetic data inside a Salesforce org, the team created 4,280 task instances across 19 types of business activities and three data protection categories.
Success rate plummets with longer dialogs
The results highlight the limits of today's LLMs. In simple, single-turn tasks, even advanced models like Gemini 2.5 Pro top out at about 58 percent accuracy. But as soon as the system needs to handle multi-turn conversations - asking questions to fill in missing details - performance falls to just 35 percent.
Salesforce ran extensive tests with nine LLMs and found that most models struggle to ask the right follow-up questions. In a review of 20 failed multi-turn tasks with Gemini 2.5 Pro, nearly half failed because the model didn't ask for crucial information. Models that ask more questions perform better in these scenarios.
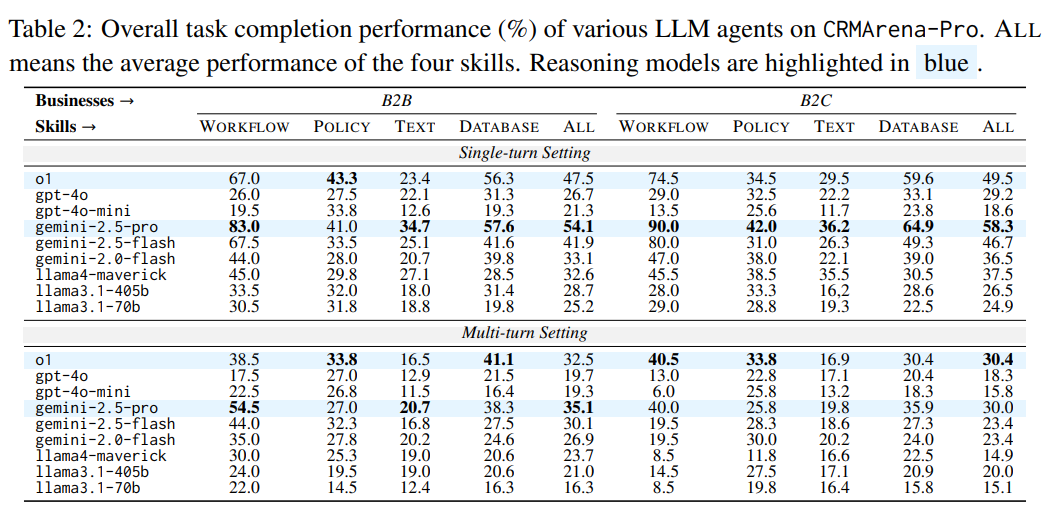
The best results came in workflow automation, such as routing customer service cases, where Gemini 2.5 Pro managed an 83 percent success rate. But accuracy dropped sharply for tasks that required understanding text or following rules, like spotting invalid product configurations or pulling information from call logs.
A previous study by Salesforce and Microsoft found similar issues: Even the most advanced LLMs became much less reliable as conversations grew longer and users revealed their needs in stages, with performance dropping by an average of 39 percent in these multi-turn scenarios.
Data privacy remains an afterthought
The benchmark also exposes gaps in data privacy. By default, LLMs almost never recognize or refuse requests for sensitive information, such as personal details or internal company data.
Only by tweaking the system prompt to explicitly reference privacy guidelines did models start to reject these requests, but at the expense of their overall performance. For example, GPT-4o increased its detection of confidential data from zero to 34.2 percent, but its task completion rate dropped by 2.7 points.
Open-source models like LLaMA-3.1 were even less responsive to prompt adjustments, suggesting they need better training to follow prioritized instructions.
Kung-Hsiang Steeve Huang, one of the authors, notes that data protection tests have rarely been included in benchmarks until now. CRMArena-Pro is the first systematic effort to measure this dimension.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.