Stability AI's Stable Diffusion 3 preview boasts superior image and text generation capabilities

Stability AI announces the preview release of Stable Diffusion 3, which shows significantly improved overall generation quality in early demos.
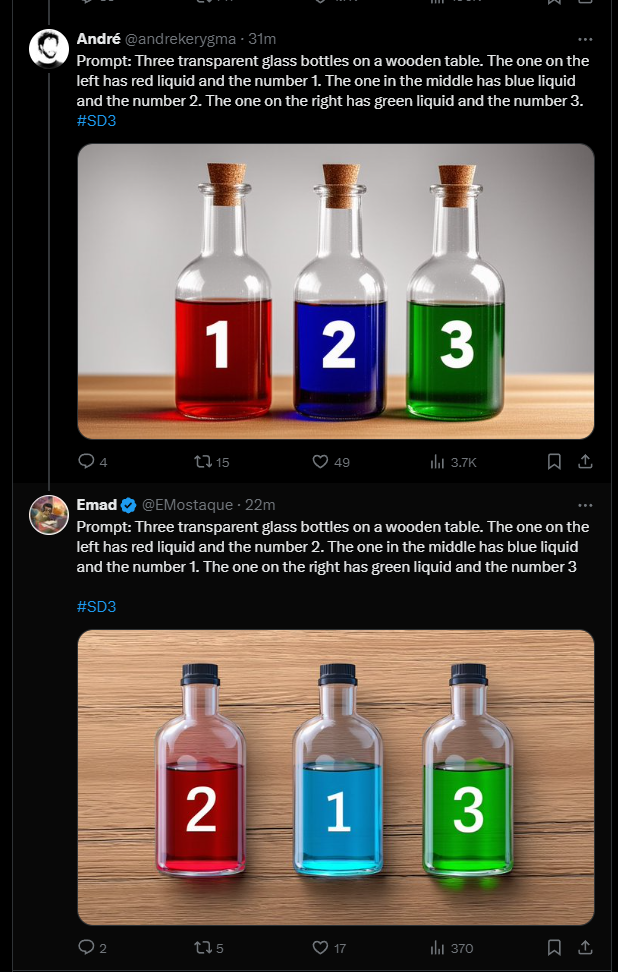
Specifically, Stability AI promises improved performance on multi-part, complex prompts, image quality, and text writing capabilities. Stability AI CEO Emad Mostaque shows an example of how accurately Stable Diffusion 3 executes a complex prompt.

Whether it always works this reliably, and how many attempts per image are needed to achieve such a result, remains to be seen in practice. According to Mostaque, the image was generated with an untuned base model of Stable Diffusion 3. The demos on X so far suggest an even better prompt following than OpenAI's DALL-E 3, which is currently the best in class in this category.
Stable Diffusion 3 models range from 800 million to 8 billion parameters and combine new image generation research from recent years, including the Diffusion Transformer Architecture with Flow Matching. A detailed technical report will be released shortly, Stability AI says.
The model is not yet generally available, but there is a waiting list that you can sign up for here. The preview phase is used to improve performance and safety before the "open release," the company states.



Stability AI says it has taken numerous safety precautions to prevent the model from being misused by malicious actors, starting with training and continuing through testing, evaluation, and deployment.
The company emphasizes ongoing collaboration with researchers, experts, and the community in the development and public use of the model. Because they are open source and fine-tunable, Stable Diffusion models are easy targets for misuse in controversial AI imaging applications.
Stable Diffusion has also been criticized and sued over its training data. For Stable Diffusion 3, artists removed millions of works from the training data in advance. Stability AI avoided this issue in the announcement of Stable Diffusion 3.
Stability AI has recently released several new models, including Stable Cascade, a very fast text-to-image model. Other new models include Stable Video Diffusion (SVD), a generative video model that produces AI-generated videos with improved motion and consistency, and Stable Zero123, a model for text-to-3D applications.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.