
Large language models show impressive capabilities. Are they just superficial statistics - or is there more to them?
Systems such as OpenAI's GPT-3 have shown that large language models have capabilities that can make them useful tools in areas as diverse as text processing and programming.
With ChatGPT the company has released a model that puts these capabilities in the hands of the general public, creating new challenges for educational institutions, for example.
Are language models under- or overrated?
Impressive capabilities quickly lead to the overestimation of AI systems like ChatGPT. Yet the debates about GPT-3 in 2019 still seem to have an impact today: ChatGPT is rarely mentioned in the media as a direct precursor to general artificial intelligence.
This is also because the systems repeatedly make absurd miscalculations, hallucinate facts or draw incorrect conclusions. Such examples show what the models lack: logical reasoning and a physically grounded model of the world.
In research, language models, therefore, become the subject of debates about the role of syntax and semantics, non-linguistic and linguistic knowledge, and the differences between thinking and speaking.
A central debate is whether language models learn only surface statistics - that is, whether they are "stochastic parrots" - or whether they learn internal representations of the process that generates the sequences they see. In other words, does a language model simply parrot what it has memorized, or has it learned models of language that internally represent, for example, grammar rules or programming language syntax?
Of birds playing Othello
A new paper by researchers at Harvard University, the Massachusetts Institute of Technology, and Northeastern University now provides arguments for the second position.
The team trained a GPT model (Othello-GPT) with Othello moves to predict new legal moves. After training with moves, the error rate in predicting legal moves was 0.01 %. An untrained Othello GPT had an error rate of 93.29 %. The researchers then investigated whether internal representations of the game could be found in the artificial neural network.
To illustrate the criteria that should be used to attribute an internal model to a system, the researchers provide a thought experiment:
Imagine you have a friend who enjoys the board game Othello, and often comes to your house to play. The two of you take the competition seriously and are silent during the game except to call out each move as you make it, using standard Othello notation. Now imagine that there is a crow perching outside of an open window, out of view of the Othello board. After many visits from your friend, the crow starts calling out moves of its own—and to your surprise, those moves are almost always legal given the current board.
This raises the question of how the crow realizes this ability. The team suggests two possibilities:
- Is it producing legal moves by "haphazardly stitching together" superficial statistics, such as which openings are common or the fact that the names of corner squares will be called out later in the game?
- Or is it somehow tracking and using the state of play, even though it has never seen the board?
No clear answer can be given by analyzing the behavior of the crow alone. But one day, while cleaning the window, we discover a grid-like arrangement of two kinds of birdseed - and this arrangement is strikingly similar to that of our last Othello game.
In the next game, we observe the crow:
Sure enough, the seeds show your current position, and the crow is nudging one more seed with its beak to reflect the move you just made. Then it starts looking over the seeds, paying special attention to parts of the grid that might determine the legality of the next move.
We decide to trick the crow: we distract it and arrange some seeds in a new position.
When the crow looks back at the board, it cocks its head and announces a move, one that is only legal in the new, rearranged position.
At this point, we have to admit to the crow that its skills are based on more than just superficial statistics. It has learned a game model that we can understand and use to control its behavior.
Of course, there are things that Crow does not represent:
What makes a good move, what it means to play a game, that winning makes you happy, that you once made bad moves on purpose to cheer up your friend, and so on.
So did the crow "understand" Othello, is it "intelligent"? The researchers step back from answering such questions for now, but "we can say, however, that it has developed an interpretable (compared to in the crow’s head) and controllable (can be changed with purpose) representation of the game state."
Othello-GPT as a synthetic test for large language models.
In our thought experiment, the crow externalizes its Othello model and makes it interpretable to us. Now, nature rarely does us the favor of externalizing internal representations in this way - a core problem that has led to decades of debate about cognition in animals. The discovery of place cells in rats was therefore a Nobel Prize-worthy discovery: it proved that there is something to the idea that biological brains build models of their environment.
Internal representations in neural networks, on the other hand, are much easier to study, and the team is using them to test their neural "crow" Othello-GPT. The researchers train 64 independent small neural networks (MLPs) whose task is to classify each of the 64 squares of the Othello game board into three states: black, blank, and white. However, the input is not the game board, but the internal representations of the Othello GPT. If these represent the game board, the final trained MLPs should be able to perform their task.
The team is able to show that the error rate of the classifiers drops to 1.7 percent as a result of the training. This, they say, indicates that there is a "world model" of the game in the internal representation of Othello-GPT. A visualization of the vectors of the MLPs also shows that training creates an emergent geometry that represents the game board, they said.
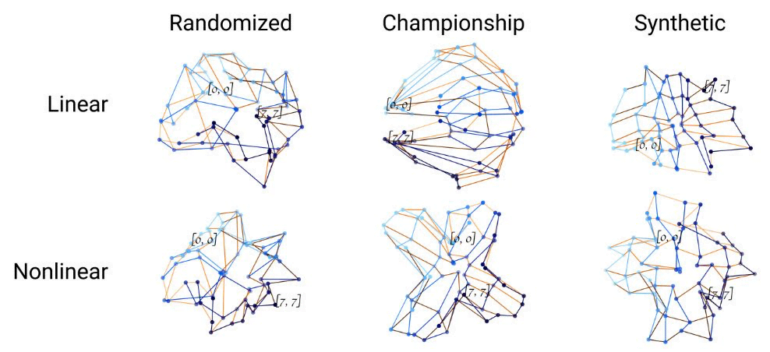
But does the GPT model use this model predict new moves? To answer this question, the team changes the states of the internal model, much like we changed the crow's model in the thought experiment. In their experiment, the researchers confirm that selectively changing the representation of the state of a board, which is important for predicting the next move, does indeed change the prediction.
They say this shows that Othello-GPT not only builds an internal model of the game, but also uses it to make predictions. Moreover, this finding can be used to show how a network arrives at its predictions. To this end, the researchers show a "local saliency map" that marks the fields relevant to a decision and thus reveals differences between the representations of two differently trained Othello-GPT variants.
Underestimated parrots
With Othello-GPT, the team shows that GPT models are capable of learning world models and are using them to make predictions. However, making the leap from the game board to natural language is difficult:
For real LLMs, we are at our best only know a small fraction of the world model behind. How to control LLMs in a minimally invasive (maintaining other world representations) yet effective way remains an important question for future research.
The team, therefore, proposes to approach the study of large language models by using more complex games and grammar tools with synthetic data.
However, the work is already contributing to a better understanding of the architecture of transformers and language models and is consistent with other research that has found evidence in GPT models of internal representations of simple concepts such as color or direction.
If these results are confirmed in large language models, we should probably think about placing them at least somewhere between stochastic parrots and real crows.




