Supersimple fine-tunes GPT-4 and sees diminishing returns in performance leaps

Data analysis platform Supersimple recently fine-tuned GPT-4, but despite considerable progress, finds the results somewhat underwhelming.
Supersimple, a data analysis platform that allows users to perform complex ad-hoc queries in natural language, received early access to OpenAI's GPT-4 fine-tuning API a few weeks ago.
The company uses large language models like GPT-3.5 and GPT-4 to answer user queries in natural language. The LLMs have been tuned for three epochs each on a proprietary dataset of tens of millions of tokens with examples of question-answer combinations.
The models output their own domain-specific language (DSL), which is then compiled into JSON and database queries. Unlike text-to-SQL, the output is an explainable no-code exploration that interacts directly with the data platform and is easily editable.
Video: Supersimple
The complex output is broken down into individual blocks representing logical steps in the thought process. The complexity of creating correct SQL queries is shifted to the platform. When generating the output, the models also consider existing dashboards and user-defined concepts.
GPT-4 fine-tuning scales less than GPT-3.5
A comparison of OpenAI-based models shows that while a fine-tuned GPT-4 outperforms GPT-3.5 by 56 percent, the performance jump is smaller than that from GPT-3 to GPT-3.5. Nevertheless, the fine-tuned GPT-4 significantly outperforms the standard GPT-4 and GPT-3.5.

Despite performance improvements, the fine-tuned GPT-4 still showed weaknesses in broad and open-ended questions when they were supposed to be solved with a single answer, according to Supersimple's internal benchmark test with 100 different questions.
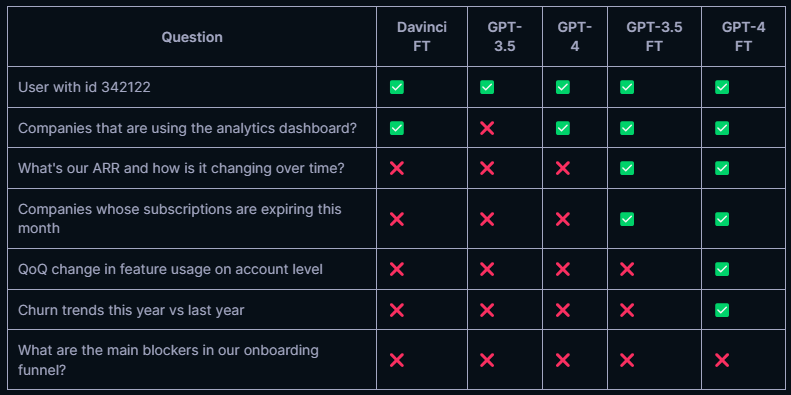
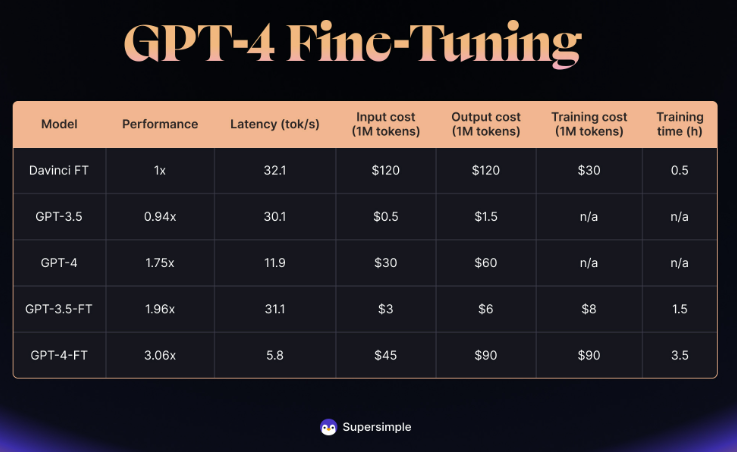
"Worryingly, there is an observable trend of diminishing returns from fine-tuning. While fine-tuned Davinci showed marked improvement over its base model, fine-tuned GPT-3.5 offered lesser gains, and the progress achieved by fine-tuning GPT-4 was even smaller," the company writes.
The main issues with the fine-tuned GPT-4, according to Supersimple, are the significantly higher latency, which is six times higher than GPT-3.5, and the costs, which are 15 times higher for inference and 11 times higher for training compared to GPT-3.5.
To overcome these limitations, Supersimple rarely relies on a single model call in production. Instead, it uses a mix of specialized models, prompts, and heuristics to improve both accuracy and response time.
Also due to high latency, Supersimple uses GPT-4 only for a specific subset of questions and for some of the most critical thinking steps. For the rest, other models such as GPT-3.5 are used.
For many real-world applications that require non-trivial reasoning skills, a single model with a single answer is not sufficient, and it is important for an AI to explain its results accurately to the user, the company says.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.