Tencent's Hunyuan-T1 reasoning model matches OpenAI's o1 capabilities in benchmarks

Tencent says its new Hunyuan-T1 model can go toe-to-toe with OpenAI's best reasoning systems.
Following the approach used for all large reasoning models, Tencent relied heavily on reinforcement learning during development, with 96.7 percent of post-training computing power focused on improving logical reasoning and alignment with human preferences.
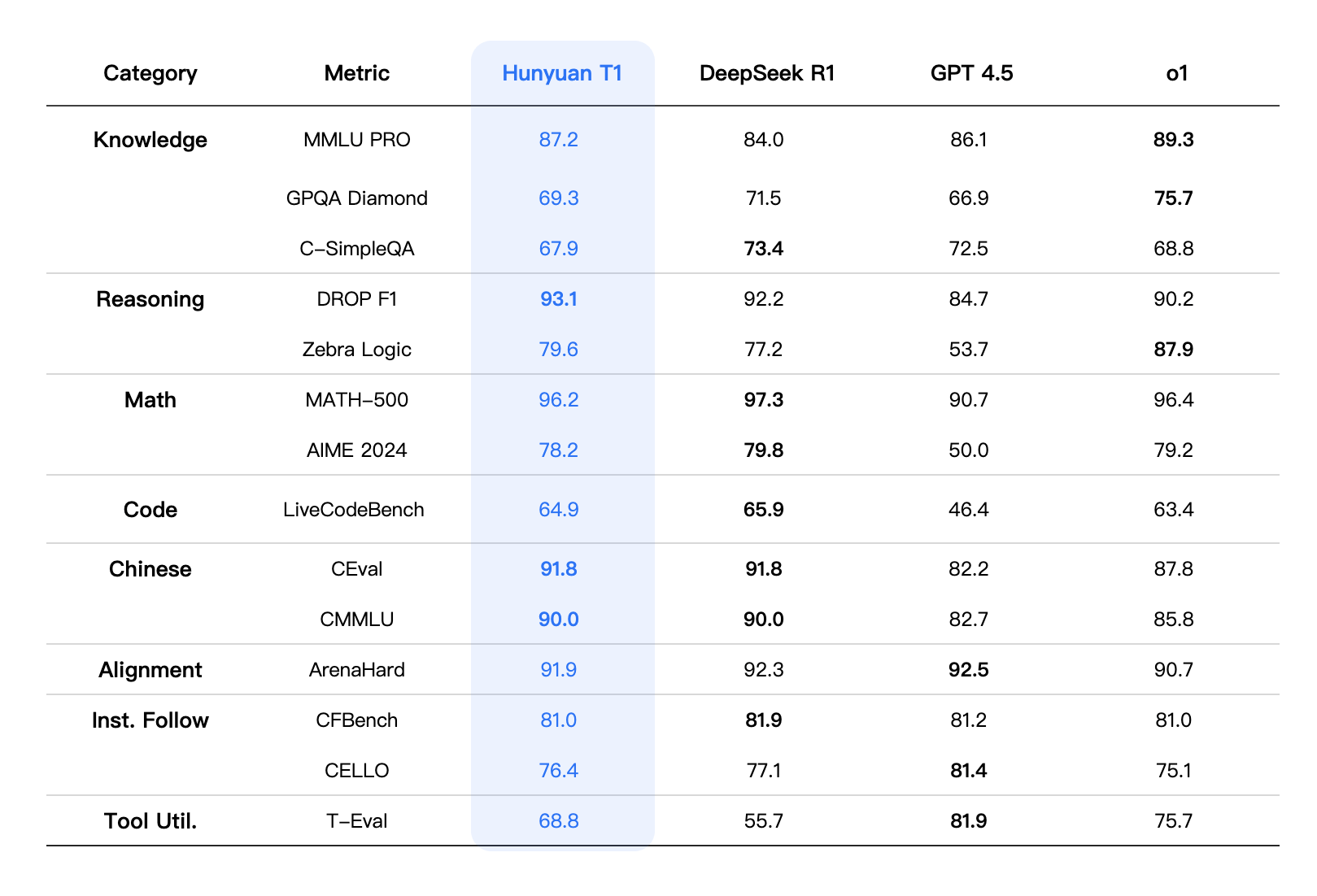
On MMLU-PRO, which tests knowledge across 14 subject areas, Hunyuan-T1 scored 87.2 points, placing second behind OpenAI's o1. For scientific reasoning, it achieved 69.3 points on the GPQA-diamond test.
Tencent says the model particularly excels in math. It achieved 96.2 points on the MATH-500 benchmark, placing just behind Deepseek-R1. Additional strong performances include LiveCodeBench (64.9 points) and ArenaHard (91.9 points).
For training, Tencent implemented a curriculum learning approach, gradually increasing task difficulty. The company also developed a self-reward system where earlier versions of the model evaluated newer versions' outputs to drive improvements.
The model uses the Transformer Mamba architecture, which Tencent says processes long texts twice as fast as conventional models under similar conditions. Hunyuan-T1 is available through the Tencent Cloud, with a demo available at Hugging Face.
This release follows Baidu's recent introduction of its own o1-level model, and Alibaba's before that. Alibaba, Baidu and Deepseek are all pursuing open-source strategies. AI investor and former Google China chief Kai-Fu Lee describes these developments as an existential threat to OpenAI.
Benchmarks are just that
As top models regularly achieve over 90 percent accuracy on standard tests, Google Deepmind has introduced a more challenging benchmark called BIG-Bench Extra Hard (BBEH). Even the best models struggle with this new test - OpenAI's top performer, o3-mini (high), achieved only 44.8 percent accuracy.
The more surprising result was that Deepseek-R1, despite its strong performance on other benchmarks, scored only around seven percent. This disparity shows that benchmark results don't tell the whole story and rarely reflect real-world performance, especially since some model teams optimize specifically for these tests. Some Chinese models have specific problems, such as inserting Chinese characters into English responses.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.