Text-to-avatar: TECA is a generative AI for digital humans

Researchers demonstrate a new method for creating and editing 3D avatars using Stable Diffusion and a new hybrid 3D representation of digital humans.
Emerging techniques in artificial intelligence are enabling the creation of increasingly realistic virtual avatars of humans. Two recent research projects from the Max Planck Institute for Intelligent Systems and others now demonstrate approaches that disentangle different components of an avatar, such as body, clothing, and hair, to enable editing operations, and even generative text-to-avatar capabilities.
Disentangling body, clothing and hair helps with generation
In a paper titled "DELTA: Learning Disentangled Avatars with Hybrid 3D Representations," the researchers present a method for creating avatars with separate layers for body and clothing/hair. Their key idea is to use different 3D representations for different components: The body is modeled with an explicit mesh-based model, while clothing and hair are represented with a Neural Radiance Field (NeRF) that can capture complex shapes and appearance.
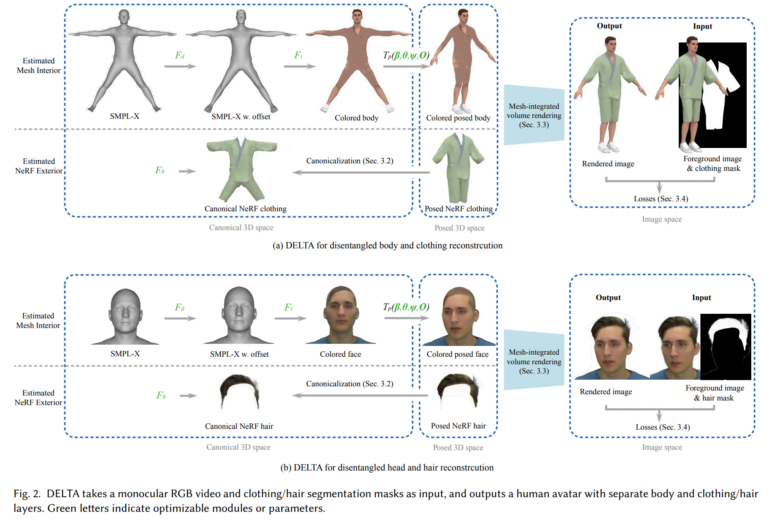
To create a new avatar, DELTA only needs a monocular RGB video as input. Once trained, the avatar enables applications such as virtual clothing fitting or shape editing. Clothing and hair can be seamlessly transferred between different body shapes.
Video: Feng et al.
Text-to-avatar method TECA uses DELTA
In "TECA: Text-Guided Generation and Editing of Compositional 3D Avatars", the researchers then tackle the task of creating avatars from text descriptions only. For this, they use Stable Diffusion and the hybrid 3D representations developed in DELTA.
The system first generates a face image from the text description using Stable Diffusion, which serves as a reference for the 3D geometry, and then iteratively paints the mesh with a texture. It then sequentially adds hair, clothing, and other elements using NeRFs guided by CLIP segmentations.
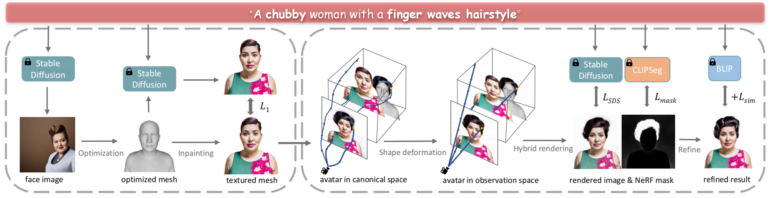
The compositional avatars generated by this method exhibit significantly higher quality than previous text-to-avatar techniques. Critically, the disentanglement also enables powerful editing via attribute transfer between avatars, the researchers say.
More information, examples, and code are available on DETLA's and TECA's GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.