The Allen Institute for AI has unveiled a new advanced AI model called Unified-IO 2. It may herald the next generation of models like GPT-5.
It is the first model that can process and produce text, image, audio, video, and action sequences. The 7-billion-parameter model was trained from scratch on a wide range of multimodal data and can be guided by prompts.
Multimodal Unified-IO 2 was trained with billions of data points
Unified-IO 2 was trained on 1 billion image-text pairs, 1 trillion text tokens, 180 million video clips, 130 million images with text, 3 million 3D assets, and 1 million robot agent motion sequences. In total, the team combined more than 120 datasets into a 600-terabyte package covering 220 visual, linguistic, auditory, and action tasks.
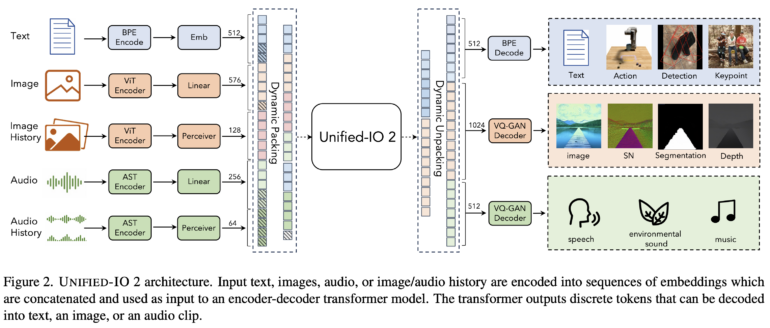
The encoder-decoder model makes several architectural changes to stabilize training and make effective use of multimodal signals, paving the way for larger and more powerful multimodal models.
Unified-IO 2 is unique to date
The training enables Unified-IO 2 to process, understand, and produce text. For example, the model can answer questions, compose a text based on instructions, and analyze text content. The model can also recognize image content, provide image descriptions, perform image processing tasks, and create new images based on text descriptions.
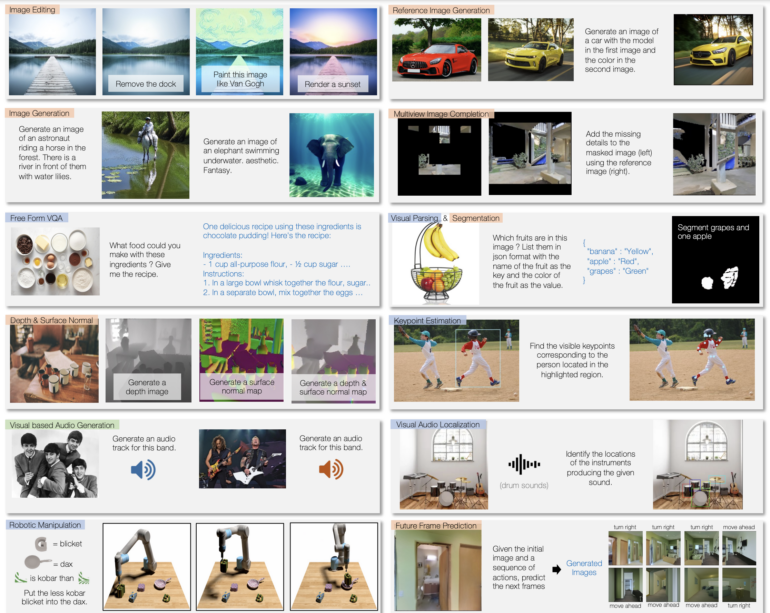
It can also generate music or sounds based on descriptions or instructions, as well as analyze videos and answer questions about the video. By training with robot data, Unified-IO 2 can also generate actions for robotic systems, e.g. converting instructions into action sequences for robots. Thanks to multimodal training, it can also process the different modalities and, for example, mark the instruments of an audio track on an image.
The model performs well on over 35 benchmarks, including image generation and understanding, natural language understanding, video and audio understanding, and robot manipulation. It achieves comparable or better performance than specialized models in most tasks. It also sets a new high on the GRIT benchmark for image tasks, which tests how models deal with image noise and other problems.
Unified-IO showed what was possible before GPT-4, Unified-IO 2 before GPT-5?
Its predecessor, Unified-IO, was introduced in June 2022 and was one of the first multimodal models capable of processing images and language. Around the same time, OpenAI was testing GPT-4 internally before the company introduced the large language model with GPT-4 vision in March 2023.
Unified-IO was thus an early glimpse into the future of large-scale AI models, which have now become commonplace with OpenAI's models and Google's multimodally trained Gemini. Unified-IO 2 now shows what we can expect in 2024: New AI models that can process even more modalities, perform many tasks natively through extensive learning - and have a rudimentary understanding of interactions with objects and robots. The latter could also have a positive impact on their performance in other areas.

The team now plans to further scale Unified-IO 2, improve data quality, and transform the encoder-decoder model into an industry-standard decoder model architecture.
More information and the code can be found on the Unified-IO 2 project page.