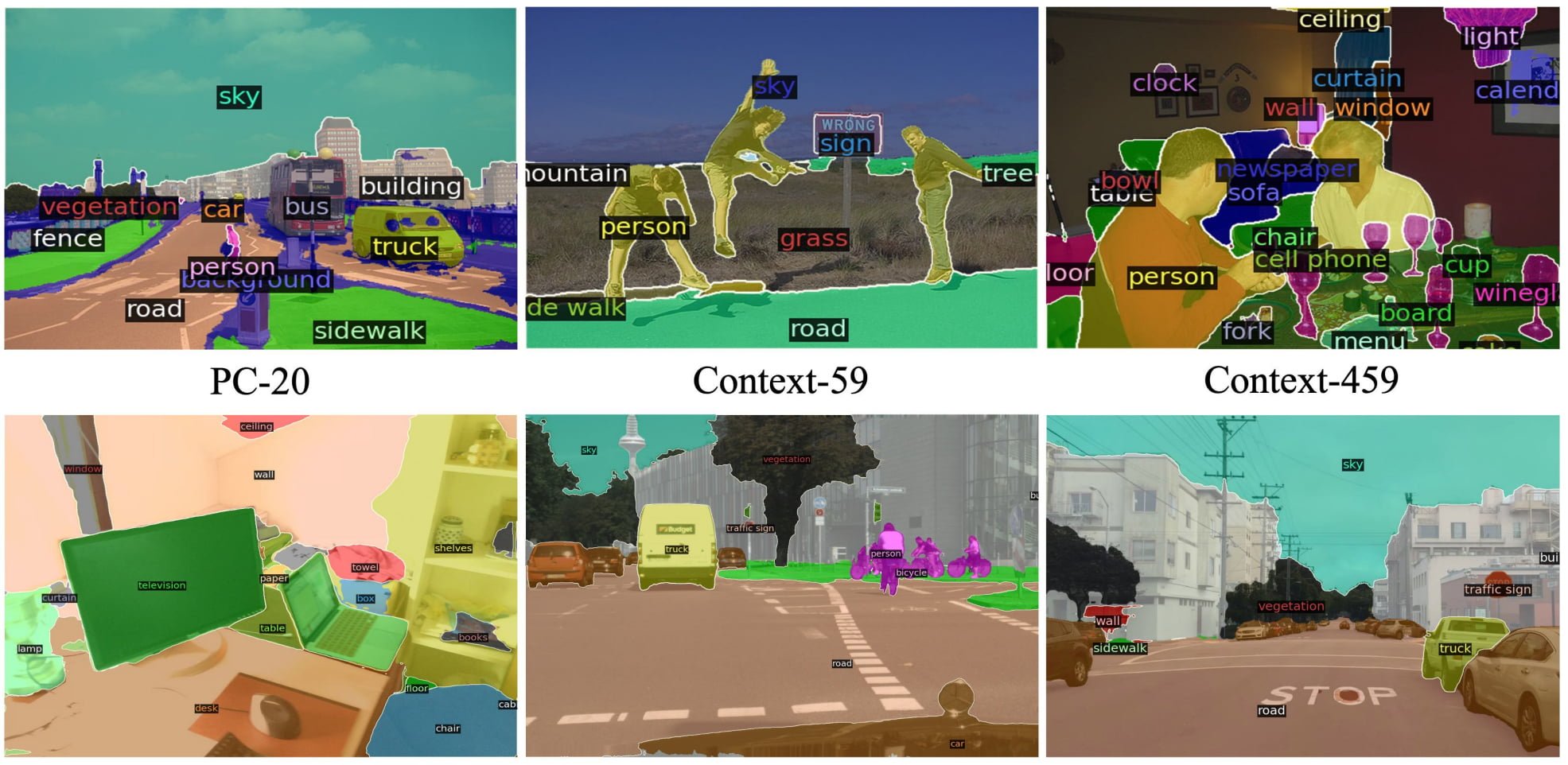
X-Decoder can perform a variety of vision and vision-language tasks. The technology could replace specialized AI models.
When it comes to visual understanding, there are numerous specialized AI models. They analyze images at different levels of granularity and perform very different tasks such as image classification, image labeling, or object recognition.
Lately, driven by the success of the Transformer architecture unveiled in 2017, the trend has been to develop general-purpose models that can be applied to numerous vision and vision-language tasks.
According to researchers at the University of Wisconsin-Madison, UCLA, and Microsoft, however, many of these models focus on image-level and region-level processing rather than pixel-level understanding. Approaches that focus on the pixel level on the other hand are tailored to specific tasks and have not yet been generalized.
X-Decoder can predict pixel-level segmentation and language tokens seamlessly
The team is introducing X-Decoder, a generalized decoding model that can process images at all levels of granularity and perform numerous vision and vision-language tasks, including pixel-level image segmentation and image captioning, for example. X-Decoder can also be combined with generative AI models such as Stable Diffusion. This approach allows for pixel-perfect image processing.
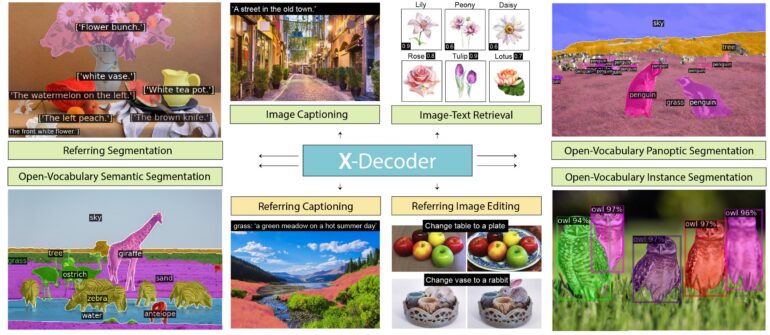
X-Decoder is built on top of a vision backbone and a transformer encoder. The model is trained with a dataset of several million image-text pairs and a limited amount of segmentation data. It processes inputs from an image encoder or a text encoder. There are two types of output: pixel-level masks and token-level semantics, such as text descriptions.

Different input and output capabilities enable X-Decoder to perform different tasks. The team noted that the use of a single text encoder also facilitates synergy between tasks.
X-Decoder shows impressive performance
According to the researchers, X-Decoder shows strong transferability to a range of downstream tasks in both zero-shot and finetuning settings. The system achieves state-of-the-art results in difficult segmentation tasks, like referencing segmentation.
Furthermore, the model offered better or competitive finetuned performance to other generalist and specialist models on segmentation and vision-language tasks. X-Decoder is flexible enough to perform novel tasks such as referring captioning, combining referring segmentation and captioning.

We present X-Decoder, a model that seamlessly supports pixel-level and image-level vision-language understanding. With a simple and generalized design, X-Decoder can unite and support generic segmentation, referring segmentation and VL tasks effortlessly, achieving strong generalizability and competitive or even SoTA performance. We hope this work can shed a light on the design of the next-generation general-purpose vision system.
From the paper
You can find more information about X-Decoder on its GitHub page. On GitHub, you can also find the code.





