Alibaba's EMO AI creates realistic talking heads from just one image and an audio track

One image, one audio track - and your lip-synchronized deepfake, almost indistinguishable from the real thing, is ready. Alibaba's latest AI model "EMO" is not yet available, but the implications are clear.
Researchers at Alibaba Group have developed a novel framework called EMO that improves the realism and expressiveness of talking video heads. EMO uses a direct audio-to-video synthesis approach based on Stable Diffusion, eliminating the need for intermediate 3D models or facial markers. The method ensures seamless transitions between frames and consistent character representation in the video.
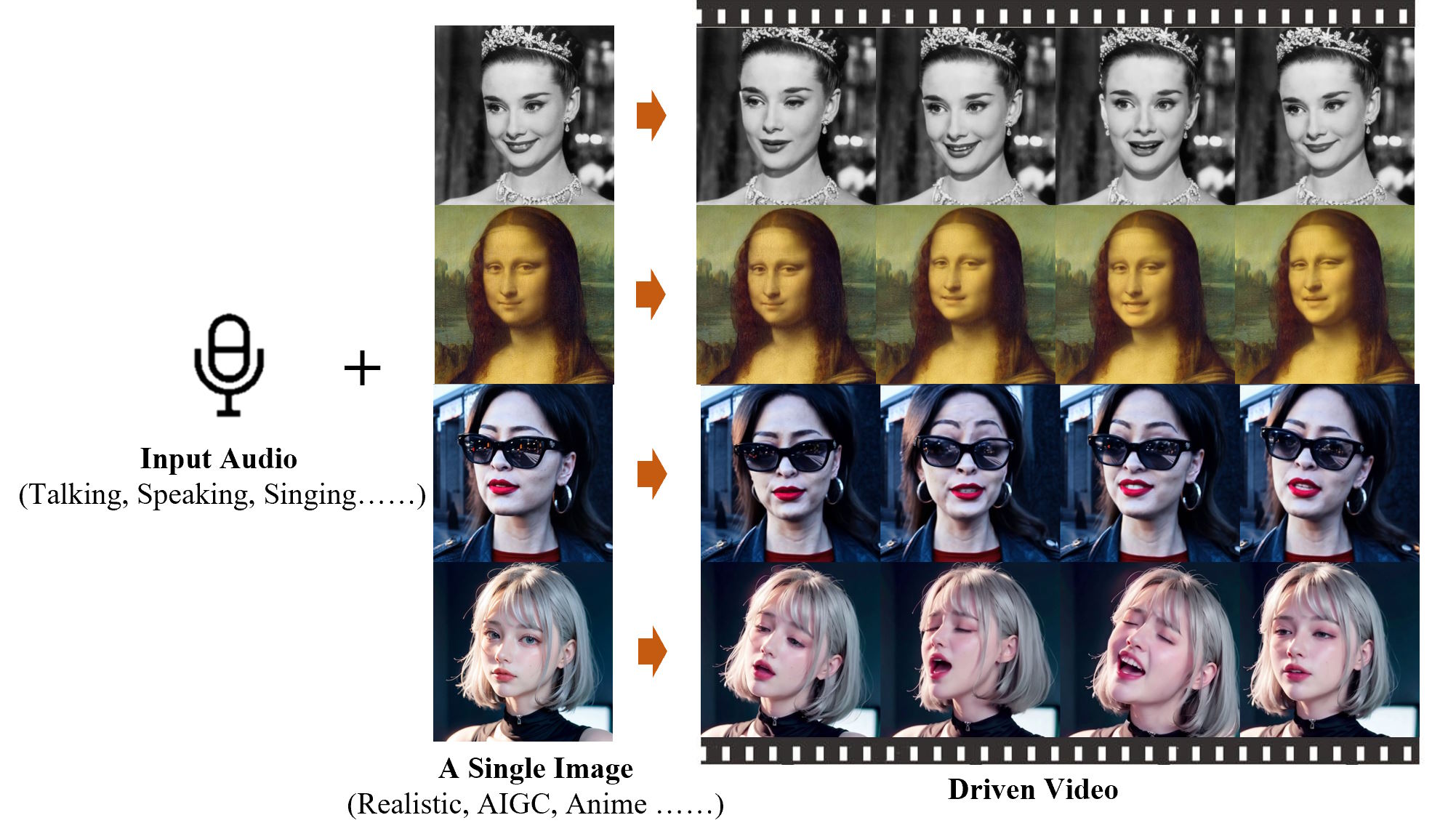
EMO can create both talking and singing videos in a variety of styles - from cartoon to anime to live action - and in different languages, significantly outperforming existing methods. Whether it's Audrey Hepburn, the Mona Lisa, or even the Japanese lady from a famous Sora demo video, a single image and soundtrack is all it takes to make lips and facial muscles move.
Video: Tian et al.
Video: Tian et al.
Video: Tian et al.
One of the biggest challenges for the researchers was the instability of the videos generated by the model, which often manifested itself in the form of facial distortion or jittering between video frames. To solve this problem, they integrated control mechanisms such as a velocity controller and a face area controller. These controls act as hyperparameters and serve as subtle control signals that do not affect the variety and expressiveness of the final generated videos.

Custom training dataset with 250 hours of footage
EMO was trained on a custom audio-video dataset containing more than 250 hours of material and well over 150 million images. This extensive dataset covers a wide range of content, including speeches, movie and TV clips, and voice recordings in multiple languages. The researchers do not reveal the exact source of the data in their paper.
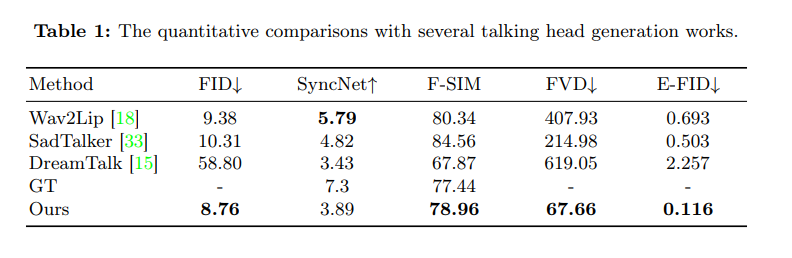
In extensive experiments and comparisons with the Human Dialogue Talking Face (HDTF) dataset, the EMO approach outperformed the current best competing methods on several metrics, including Fréchet Inception Distance (FID), SyncNet, F-SIM, and FVD.
While EMO represents a significant advance in the field of video generation, the researchers acknowledge some limitations. The method is more time-consuming than others that do not rely on diffusion models. Also, without explicit control signals to guide the figure's movement, the model may inadvertently generate other body parts. Future work will likely address these challenges.
It is not clear if and where Alibaba Group intends to apply this research and make it available to users. Such technologies offer an enormous potential for abuse if they can be used to create realistic deepfake videos in a very short time and, in combination with one of the numerous audio deepfake tools, to put all kinds of words into the mouths of politicians, for example. Especially in the US election year 2024, experts are very concerned about the risks of deepfakes.
But these developments are also exciting for entertainment and could be used in social media applications such as TikTok or in the film industry for more realistic dubbing.
Recently, several companies have been working on AI lip-syncing, including AI startup Pika Labs. The company, which offers a promising AI video model, just added lip-syncing to its product recently.
Another prominent player in the field is HeyGen, which made a splash last year with a convincing combination of voice cloning and lip-syncing.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.